Valutare le prestazioni di un sistema Linux mediante Tracealyzer
-

- Tweet
- Pin It
- Condividi per email
-
Quando si sviluppa un’applicazione basata su Linux, è importante configurare il sistema in modo da ottimizzare le prestazioni poichè una configurazione non idonea potrebbe penalizzare le prestazioni dell’applicazione stessa. Personalmente ho fatto parte di un team coinvolto nello sviluppo di un’applicazione che prevedeva la ricezione e l’elaborazione dei dati provenienti da una radio basata sulla tecnologia SDR (Software Defined Radio). I dati venivano trasmessi dall’SDR a una velocità molto elevata ed era importante minimizzare la perdita di pacchetti. Sfortunatamente abbiamo rilevato una sostanziale perdita di pacchetti nella fase di bring-up del sistema Linux, per cui urgeva determinarne la causa. E’ stato quindi ipotizzato che la cosiddetta affinità della CPU non fosse stata impostata correttamente nell’applicazione.
A quel tempo (nel 2017) non avevo accesso a Tracealyzer per Linux di Percepio e l’ipotesi avanzata si era dimostrata errata. In questo articolo verrà riesaminato il problema per vedere come Tracealyzer possa aiutare a scoprire perchè l’ipotesi formulata non fosse corretta e ad acquisire i risultati. Non potendo disporre del sistema, dell’applicazione e dell’SDR originali, mi sono servito di sostituti. Il sistema Linux è stato sostituito da Jetson Nano, l’applicazione dello spazio utente è stata sostituita da “iperf”, mentre un altro sistema Linux è stato utilizzato per sostituire l’SDR. “Iperf” è una utility comunemente utilizzata per collaudare le prestazioni di una connessione di rete tra due sistemi Linux. Nella figura 1 è riportata la configurazione base dell’esperimento.
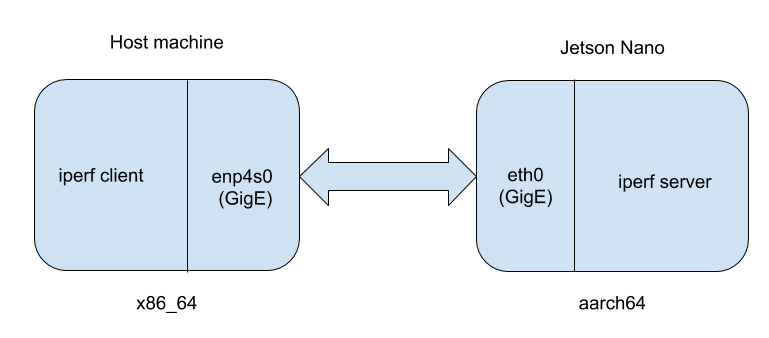
Fig. 1 – Schema della configurazione utilizzata per l’esperimento
Sulla destra è visibile Jetson Nano (architettura ARM a 64 bit) che fa girare “iperf” in modalità server. Sulla sinistra vi è la macchina host (architettura x86 a 64 bit) che fa girare iperf in modalità client. L’obiettivo è regolare l’affinità della CPU del server iperf su Jetson Nano per osservare in che modo quel parametro influisca sul throughput complessivo tra client e server.
Il termine affinità della CPU indica il particolare core della CPU al quale viene assegnato un contesto di esecuzione. Solitamente questo viene impostato in base all’applicazione. L’ipotesi fatta è che se l’affinità dell’interrupt e del relativo gestore corrisponde all’affinità del processo che riceve i pacchetti, la perdita di pacchetti dovrebbe essere minimizzata in quanto non si perde tempo a spostare i dati tra i core.
In primo luogo si determinerà l’affinità dell’interfaccia eth0 di Jetson Nano. Ciò indicherà quale core del processore gestisce gli interrupt dell’interfaccia eth0. Per far ciò bisogna bisogna eseguire i seguenti comandi su Jetson Nano:
$> cat /proc/interrupts/ | grep eth0
407: 1881331 0 0 0 Tegra PCIe MSI 0 Edge eth0
Possiamo vedere che il primo core (CPU0) gestisce questi interrupt. Successivamente faremo girare iperf in modalità server su Jetson Nano:
$> iperf -s -B 192.168.2.247 -p 5001
Ancora su Jetson Nano eseguiamo i seguenti comandi per determinare l’affinità di CPU predefinita:
$> ps ax | grep iperf
12910 pts/0 Sl+ 1:25 iperf -s -B 192.168.2.247 -p 5001
$> taskset -p –cpu-list 12910
pid 20977’s current affinity list: 0-3
Il primo comando recupera il PID (Process ID) del comando iperf. Abbiamo specificato tale PID nel comando taskset, insieme al parametro –cpu-list per determinare a quale core del processore sia consentito far girare iperf. Inizialmente abbiamo visto che ciascun core del processore può far girare iperf.
Quindi facciamo girare iperf in modalità client dalla nostra macchina host eseguendo il seguente comando che, eseguito, indica che stiamo cercando di inviare 1 Gbps di dati al server (si può vedere che ci stiamo avvicinando molto a questo limite):
$> iperf -b1G -c 192.168.2.247 -p5001
[ 3] 0.0-10.0 sec 1.10 GBytes 851 Mbits/sec
Consideriamo adesso cosa accadrebbe se non consentissimo a Linux di scegliere il core del processore ottimale e assegnassimo invece l’esecuzione del server iperf a un core specifico. Penalizziamo in modo artificioso il nostro setup per valutarne l’impatto sul throughput. Per fare ciò assegniamo il server iperf alla CPU3 (è bene ricordare che la CPU0 è responsabile della gestione degli interrupt dell’interfaccia eth0) mediante il seguente comando su Jetson Nano:
$> taskset -p –cpu-list 3 12910
pid 20977’s current affinity list: 0-3
pid 20977’s new affinity list: 3
Facendo ancora girare iperf, otteniamo lo stesso valore medio di throughput pari a 851 Mbps. Poiché avevo ipotizzato che ci sarebbe voluto più tempo per trasferire i dati dalla CPU0 alla CPU3, il throughput avrebbe dovuto diminuire, ma ciò non è successo. Tracealyzer ci aiuta a scoprirne il motivo.
In primo luogo, avviamo un’acquisizione lttng su Jetson Nano:
$> lttng create
$> lttng enable-event -k -a
$> lttng enable-event -u –all
$> lttng add-context -k -t pid
$> lttng add-context -k -t ppid
$> lttng start
Quindi facciamo girare un test iperf dalla macchina host, arrestiamo lttng ed eliminiamo la sessione per evitare di avere trace di ampie dimensioni con eventi estranei.
$> lttng stop
$> lttng destroy
Possiamo vedere alcuni interessanti risultati nell’acquisizione quando iperf è assegnata alla CPU3. In primo luogo, si nota che ci sono quattro istanze del processo iperf in esecuzione, anche se Linux elenca solamente una singola istanza. Successivamente si può osservare che l’istanza di iperf che corrisponde al PID riportato da Linux viene eseguita solo due volte: una volta all’inizio della misura di iperf e una volta alla fine (Fig. 2).
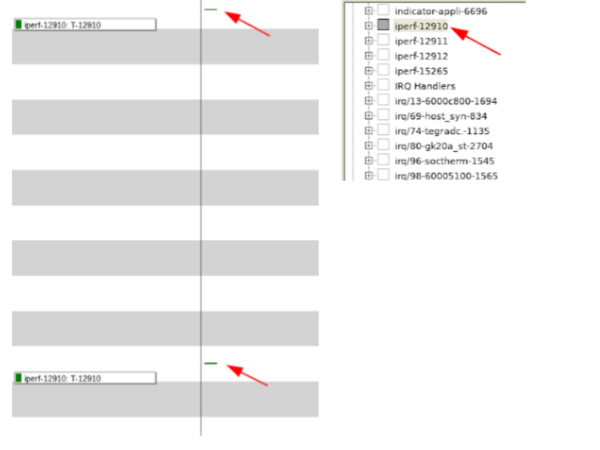
Fig. 2
Possiamo anche osservare che, nonostante avessimo assegnato iperf alla CPU3, vi sono altre istanze di iperf in esecuzione su core differenti (Fig. 3).
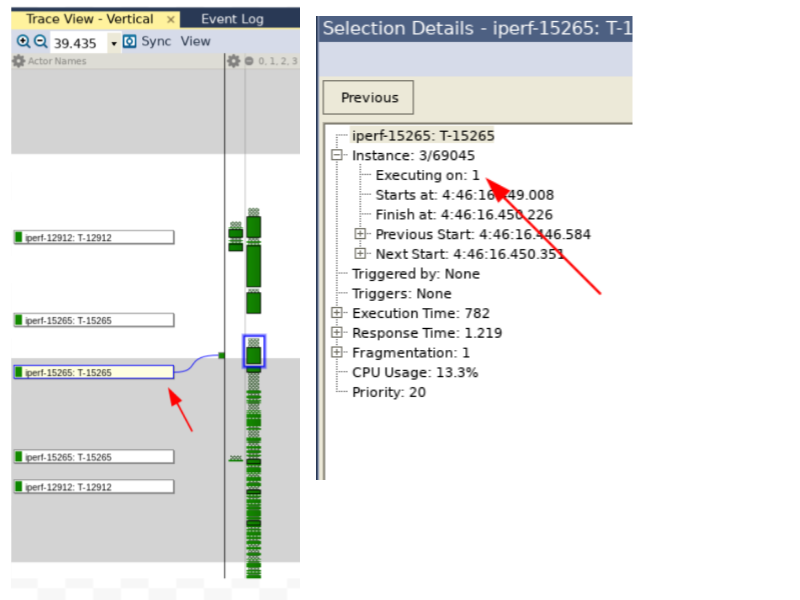 Fig. 3
Fig. 3
Sebbene avessimo istruito iperf di limitare la sua esecuzione sulla CPU3, qualcosa ha provocata la sua esecuzione su altre CPU. Questo comportamento non è così raro poiché le applicazioni possono implementare la propria logica per selezionare la CPU più idonea per l’esecuzione. Sembra in questo caso che anche iperf abbia implementato una logica simile.
Eseguendo uno zoom sul trace, è possibile osservare un gran numero di istanze di esecuzione del gestore dell’interrupt di eth0 che sono eseguite quasi allo stesso istante dell’esperimento con iperf, per cui è possibile concludere che esista una correlazione tra il momento in cui il gestore dell’interrupt di eth0 è in esecuzione e quello in cui l’istanza di iperf è in esecuzione (Fig. 4).
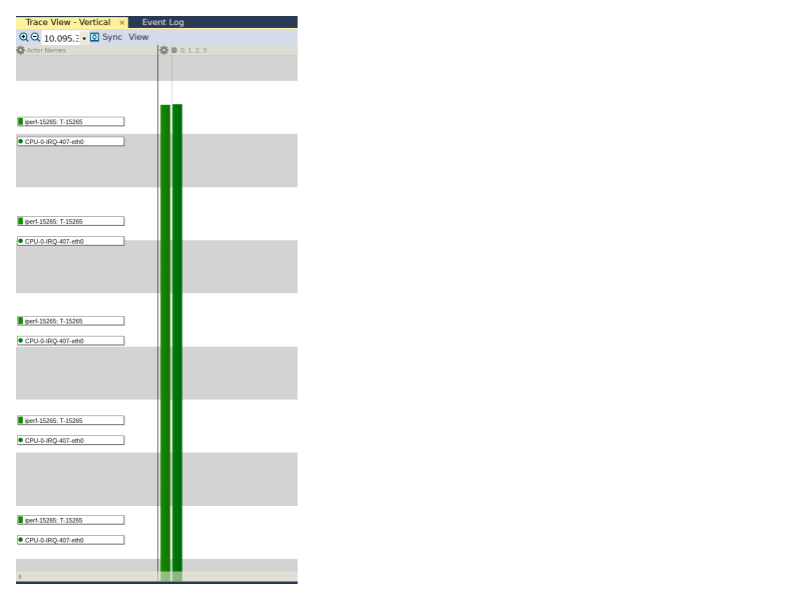
Fig. 4
Facendo un ingrandimento al centro del trace di figura 4 per focalizzare l’attenzione sulla misura del throughput (per evitare distrazioni dovute a qualsiasi scambio specifico del protocollo tra client e server iperf) appare uno schema ricorrente (Fig. 5).

Fig. 5
Effettuando un ulteriore ingrandimento del trace e misurando il tempo tra il momento in cui l’IRQ (Interrupt Handler) ha completato l’esecuzione e quello in cui ha inizio l’esecuzione di iperf, si ottiene un valore pari a 55 microsecondi (Fig. 6).
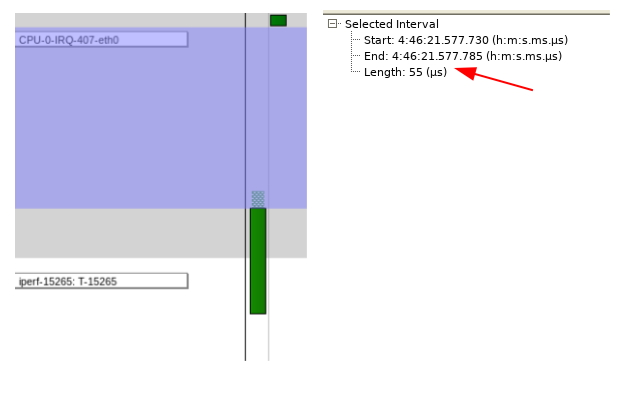
Fig. 6
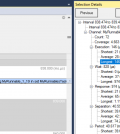
Cliccando su quella particolare istanza di esecuzione di iperf e successivamente sul simbolo “+” posto in prossimità di “Instance” nella vista “Selection details”, vediamo che questa particolare istanza di iperf è in esecuzione sulla CPU3 come previsto (Fig. 7).
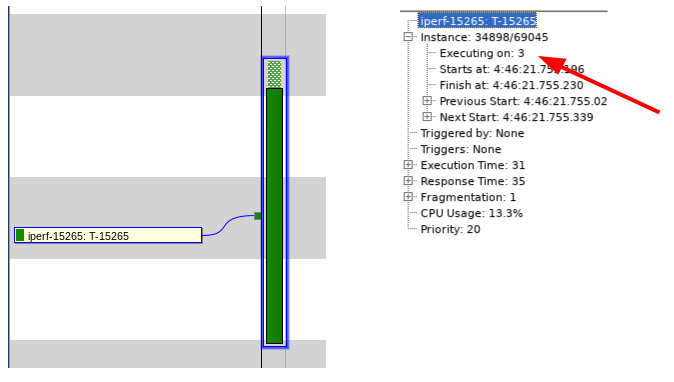
Fig. 7
Diamo per acquisito che trascorrono 55 microsecondi tra il completamento del gestore dell’interrupt di eth0 e l’inizio dell’esecuzione dell’istanza di iperf. Ora poniamo il sistema sotto carico eseguendo il seguente comando su terminale di Jetson Nano, che fa girare 20 processi su tutte le CPU:
$> stress –cpu 20
Tramite il comando top (che visualizza i processi in esecuzione e le informazioni importanti relative ad essi) è possibile vedere che su tutti e quattro i core il carico della CPU è massimo.
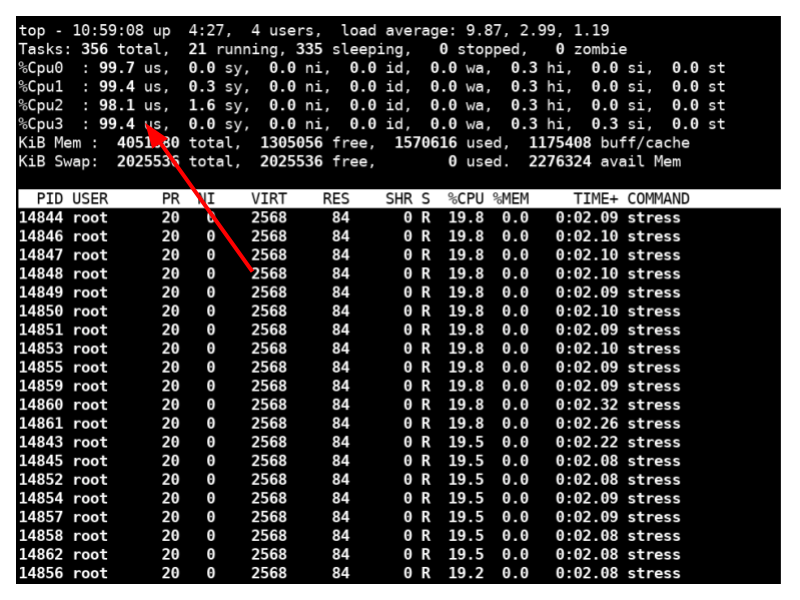
Fig. 8
Quando eseguiamo una nuova misura iperf, possiamo osservare che il throughput è ancora 851 Mbps (Fig. 9)
$> iperf -b1G -c 192.168.2.247 -p5001[ 3] 0.0-10.0 sec 1.10 GBytes 851 Mbits/sec
A questo punto apriamo Tracealyzer con un’acquisizione catturata quando abbiamo artificialmente stressato i core della CPU e ingrandiamo la parte centrale dell’acquisizione per osservare la sequenza di esecuzione dell’interrupt handler di eth0 e dell’istanza di iperf. Possiamo notare che il tempo intercorso tra il completamento dell’esecuzione del gestore dell’interrupt di eth0 e l’inizio dell’esecuzione di iperf è ora pari all’incirca a 40 microsecondi (Fig. 9).
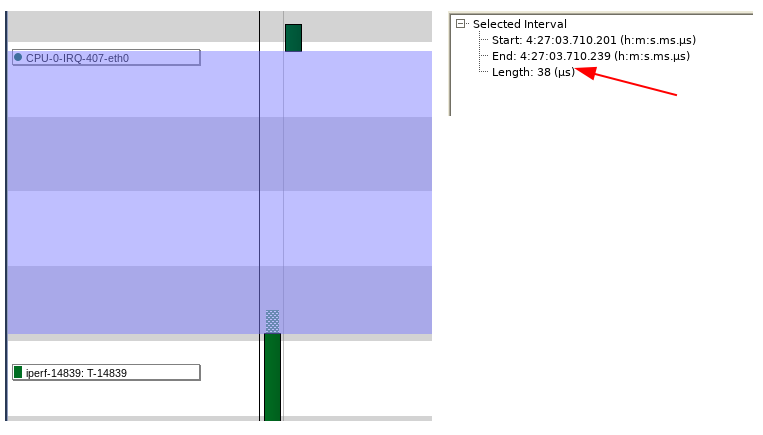
Fig. 9
Il valore assoluto in sè non è importante (anche se è interessante notare il minore carico), perchè si tratta dello stesso ordine di grandezza quanto il sistema è sotto carico e quando non lo è (40 contro 55 microsecondi). Si tratta di una caratteristica molto importante del kernel Linux che, anche in presenza un’applicazione dello spazio utente che sembra monopolizzare tutti e quattro i core del sistema, garantisce comunque che altre applicazioni dello spazio utente non restino in uno stato di attesa indefinita (starvation) delle risorse della CPU e che la comunicazione tra i core non ne risulti influenzata.
Se facciamo un passo a ritroso possiamo vedere tutti i processi che rappresentano l’applicazione con la quale abbiamo “stessato” i core della CPU, a conferma che la CPU è effettivamente sottoposta a un carico di lavoro pesante (Fig. 10).

Fig. 10
Per riassumere, in questo progetto ho utilizzato Tracealyzer per Linux per verificare un’ipotesi su come l’impostazione dell’affinità della CPU su un processo avrebbe influenzato le sue prestazioni. Analizzando le interazioni tra i differenti elementi di esecuzione in condizioni normali e sotto stress, abbiamo identificato una caratteristica peculiare del kernel Linux, ovvero l’uso dell’algoritmo “best effort”, per una equa ripartizione delle risorse della CPU a tutti i processi. Oltre a ciò, siamo andati in profondità per scoprire i motivi per i quali l’ipotesi originale (che impostando l’affinità della CPU di un processo per elaborare i pacchetti avrebbe ridotto la perdita di pacchetti) non era corretta. Infine, sebbene l’analisi non fosse esaustiva, abbiamo individuato ulteriori aree da attenzionare, come lo schedulatore Linux e il codebase iperf, su cui compiere ulteriori analisi.
Informazione sull’autore
 Mohammed Billoo, fondatore di MAB Labs, LLC (www.mab-labs.com), può vantare un’esperienza di oltre 12 anni nella definizione di architetture, progettazione, implementazione e collaudo di software embedded, con una particolare enfasi su Linux embedded. LA sua attività spazia dal bring-up di schede custom alla scrittura di software per driver di dispositivi custom e di codice applicativo. Mohammed è un attivo contributore per il kernel Linux e partecipa a numerose attività nell’ambito dell’open source.
Mohammed Billoo, fondatore di MAB Labs, LLC (www.mab-labs.com), può vantare un’esperienza di oltre 12 anni nella definizione di architetture, progettazione, implementazione e collaudo di software embedded, con una particolare enfasi su Linux embedded. LA sua attività spazia dal bring-up di schede custom alla scrittura di software per driver di dispositivi custom e di codice applicativo. Mohammed è un attivo contributore per il kernel Linux e partecipa a numerose attività nell’ambito dell’open source.
E’ professore aggiunto di Ingegneria Elettrica presso la “Cooper Union for the Advancement of Science and Art” dove insegna ai corsi di Logica digitale, Progettazione e Architetture di Computer.
Mohammed ha conseguito la laurea e il successivo master in Ingegneria Elettrica presso la stessa istituzione.
Altri blog sono disponibili agli indirizzi:
Contenuti correlati
-
 Percepio presenta la release 4.9 di Tracealyzer
Percepio presenta la release 4.9 di TracealyzerÈ disponibile la versione 4.9 di Tracealyzer, il tool di punta di Percepio per il software embedded. Questa nuova release è focalizzata sul miglioramento dell’esperienza dell’utente con le distribuzioni Linux. L’installazione, infatti, è stata notevolmente semplificata e...
-
 Cinque passi per semplificare il debug di applicazioni multithread
Cinque passi per semplificare il debug di applicazioni multithreadUn’analisi di cinque semplici pratiche che permettono di ricavare le informazioni necessarie sul comportamento real-time a livello di sistema, per migliorare la qualità del prodotto, accelerare lo sviluppo e ridurre il time-to-market Leggi l’articolo completo su Embedded...
-
 Virtualizzazione e monitoraggio remoto: un valido approccio per affrontare i problemi nella catena di approvvigionamento
Virtualizzazione e monitoraggio remoto: un valido approccio per affrontare i problemi nella catena di approvvigionamentoDevAlert Sandbox di Percepio è un esempio di come la virtualizzazione e l’emulazione hardware possano essere integrate in un package compatto, consentendo alle aziende che sviluppano prodotti edge/IoT di continuare a farlo senza dover attendere la disponibilità...
-
 Disponibile la versione 4.7 di Percepio Tracealyzer
Disponibile la versione 4.7 di Percepio TracealyzerPercepio ha annunciato la disponibilità della versione 4.7 di Tracealyzer che aggiunge numerose nuove funzionalità e significativi miglioramenti per gli sviluppatori. Tra le novità, per esempio, ci sono l’osservabilità di qualsiasi software C/C++ e il supporto per...
-
 Un’interfaccia aperta per una diagnostica dei veicoli più efficiente
Un’interfaccia aperta per una diagnostica dei veicoli più efficienteHella Gutmann, una delle più importanti aziende nel settore della diagnostica dei veicoli, ha deciso di sfruttare il know-how acquisito da Kontron per tenere il passo con l’evoluzione dei requisiti di comunicazione delle principali Case automobilistiche Leggi l’articolo...
-
 Percepio presenta DevAlert Sandbox
Percepio presenta DevAlert SandboxPercepio ha rilasciato DevAlert Sandbox, una piattaforma online “pronta all’uso” per DevAlert, il framework di monitoraggio per il rilevamento da remoto di anomalie e il debug di software basato su RTOS. “In un mondo segnato dalla presenza...
-
 Utilizzo di Tracealyzer per valutare gli algoritmi di Python in Linux
Utilizzo di Tracealyzer per valutare gli algoritmi di Python in LinuxMohammed Billoo, fondatore di MAB Labs (www.mab-labs.com), fornisce soluzioni Linux embedded per una vasta gamma di piattaforme hardware. In questa serie di articoli Billoo ci guida attraverso il supporto di Tracealyzer v. 4.4 per Linux In un...
-
Comprendere l’impatto delle opzioni di compilazione sulle prestazioni
Nel precedente articolo abbiamo discusso come utilizzare LTTng per instrumentare le applicazioni in spazio utente e visualizzare i dati di trace in Tracealyzer a scopo di indagine. In questo articolo capiremo come l’abbinamento di LTTng e Tracealyzer...
-
 Percepio migliora il supporto per Zephyr e ThreadX in Tracealyzer 4.6
Percepio migliora il supporto per Zephyr e ThreadX in Tracealyzer 4.6Percepio ha rilasciato Tracealyzer 4.6 con supporto per l’RTOS Zephyr e Azure RTOS ThreadX di Microsoft. Questa nuova versione include anche la libreria di trace di nuova generazione di Percepio con supporto migliorato per il tracing in...
-
Utilizzo di Tracealyzer per Linux per valutare le prestazioni in spazio utente
Mohammed Billoo, fondatore di MAB Labs (www.mab-labs.com), fornisce soluzioni Linux embedded per una vasta gamma di piattaforme hardware. In questa serie di articoli Billoo ci guida attraverso il supporto di Tracealyzer v. 4.4 per Linux utilizzando come...
Scopri le novità scelte per te
-
Percepio presenta la release 4.9 di Tracealyzer
È disponibile la versione 4.9 di Tracealyzer, il tool di punta di Percepio per il software embedded....
-
Cinque passi per semplificare il debug di applicazioni multithread
Un’analisi di cinque semplici pratiche che permettono di ricavare le informazioni necessarie sul comportamento real-time a livello...

News/Analysis Tutti ▶
-
 congatec compie 20 anni
congatec compie 20 annicongatec ha recentemente celebrato il suo ventesimo anniversario. Coerentemente con la propria visione, l’azienda...
-
 Partnership tra Advantech e ADATA per gli AMR
Partnership tra Advantech e ADATA per gli AMRAdvantech ha annunciato una partnership con ADATA per lo sviluppo di un robot mobile...
-
 La connettività in ambienti difficili analizzata in un eBook di Mouser e Cinch
La connettività in ambienti difficili analizzata in un eBook di Mouser e CinchMouser Electronics, in collaborazione con Cinch Connectivity Solutions, ha pubblicato un nuovo eBook intitolato...
Products Tutti ▶
-
 Un nuovo touch controller da Microchip
Un nuovo touch controller da MicrochipMTCH2120 è un nuovo touch controller a 12 pulsanti di Microchip Technology. Questo componente,...
-
 Panasonic Industry annuncia un nuova serie di relè
Panasonic Industry annuncia un nuova serie di relèPanasonic Industry ha recentemente presentato un nuovo relè PhotoMOS progettato per apparecchiature di misurazione,...
-
 Panasonic migliora la produzione di PCB
Panasonic migliora la produzione di PCBPanasonic Connect Europe ha realizzato il nuovo modular mounter NPM-GW, un modulo di montaggio...

{kind=link}