Utilizzo di Tracealyzer per valutare gli algoritmi di Python in Linux
-

- Tweet
- Pin It
- Condividi per email
-
Mohammed Billoo, fondatore di MAB Labs (www.mab-labs.com), fornisce soluzioni Linux embedded per una vasta gamma di piattaforme hardware. In questa serie di articoli Billoo ci guida attraverso il supporto di Tracealyzer v. 4.4 per Linux
In un precedente articolo abbiamo discusso come utilizzare Tracealyzer per l’analisi di applicazioni in spazio utente di un sistema embedded basato su Linux. In quell’esempio, abbiamo introdotto una nuova funzionalità e valutato le prestazioni di alcune possibili implementazioni di essa. Abbiamo capito quali funzioni invocare nella nostra applicazione in C/C++ per generare dei punti di tracciamento (tracepoint) da utilizzare poi come marcatori (marker) nella nostra sequenza temporale in Tracealyzer. Abbiamo anche appreso come convertire con Tracealyzer i tracepoint in intervalli personalizzati che in ultima istanza forniscono informazioni di temporizzazione utili a valutare la bontà delle diverse implementazioni.
In questo articolo vedremo come utilizzare Tracealyzer per valutare in modo rapido ed efficiente più implementazioni di un algoritmo scritto in Python. A causa della crescente richiesta di poter eseguire algoritmi di apprendimento automatico (machine learning), Python è sempre più utilizzato per lo sviluppo di applicazioni embedded in quanto la maggior parte dei framework di machine learning sono implementati in tale linguaggio.
Come (non) calcolare i numeri di Fibonacci
Ora analizzeremo un semplice esempio ricavandone una sorprendente lezione sullo sviluppo di applicazioni in Python. Questo esempio dimostrerà anche come la combinazione di LTTng e Tracealyzer può essere utilizzata per confrontare in modo efficace le prestazioni di due implementazioni dello stesso algoritmo.
Nello specifico, implementeremo la sequenza di Fibonacci utilizzando due tecniche molto comuni. La prima prevede l’uso di un algoritmo ricorsivo, mentre la seconda fa ricorso a un algoritmo iterativo standard. Quindi utilizzeremo LTTng e Tracealyzer per confrontare le prestazioni delle due tecniche.
In ogni caso, prima di iniziare, è necessario accertarsi che il package software LTTng per Python sia installato. Ulteriori informazioni su come installare il software necessario sono reperibili sul sito web di LTTng all’indirizzo: https://lttng.org/docs/v2.12/#doc-ubuntu.
Inizieremo con entrambe le implementazioni della sequenza di Fibonacci, che verranno eseguite in un unico modulo:
def recur_fibo(n):
if n <=1 n:
return n
else:
return(recur_fibo(n-1) + recur_fibo(n-2))
def non_recur_fibo(n):
result = []
a,b = 0,1
while a < n:
result.append(a)
a,b = b, a+b
return result
Avremo quindi il nostro file sorgente Python separato che invoca le due funzioni di cui sopra, con alcune linee chiave che sono grassetto (che saranno discusse in seguito).
import lttngust
import logging
import fib
def example():
logging.basicConfig()
logger = logging.getLogger(‘my-logger’)
logger.info(‘Start’)
fib.recur_fibo(10)
logger.info(‘Stop’)
logger.info(‘Start’)
fib.non_recur_fibo(10)
logger.info(‘Stop’)
if __name__ == ‘__main__’:
example()
A questo punto, eseguiamo i seguenti comandi per acquisite un trace da utilizzare in Tracealyzer:
$> lttng create
$> lttng enable-event –kernel sched_switch
$> lttng enable-event –python my-logger
$> lttng start
$> python3 <example source file>.py
$> lttng stop
$> lttng destroy
Nel frammento di codice sopra, il comando in grassetto è fondamentale. Qui stiamo sostituendo il logger Python standard con uno denominato “my-logger” e memorizzando questi eventi nel trace LTTng risultante. Le linee in grassetto nel frammento in Python definiscono questo logger “my-logger” e generano gli eventi relativi alle nostre funzioni di test. L’effettiva “severity” dei log può essere qualsiasi, per cui sarà ignorata. Possiamo vedere che il meccanismo utilizzato per generare eventi che contrassegnano i “confini” della funzione è simile a quello visto nel precedente articolo.
Una volta generato il trace, possiamo aprirlo con Tracealyzer e visualizzare i nostri eventi in Trace View (fig. 1).
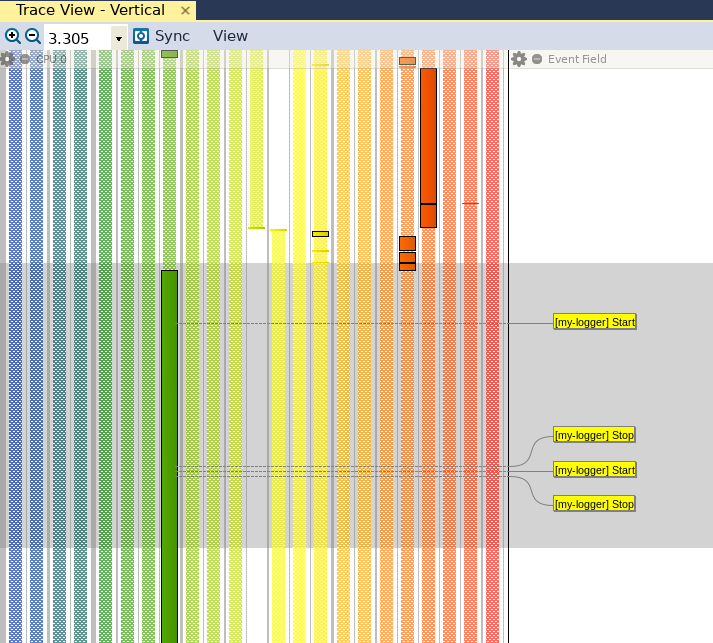
Fig. 1
Poiché in questo particolare esempio non stiamo acquisendo alcun dato, non dobbiamo configurare l’interpretazione degli eventi per leggere i valori dei dati. Tutto quello che dobbiamo fare è generare un intervallo personalizzato per contrassegnare l’entrata e l’uscita di entrambe le funzioni. Anche se nella visualizzazione con Trace View in figura 1 possiamo già vedere “ad occhio” che esistono sostanziali differenze nelle prestazioni, l’obiettivo è individuare delle metriche prestazionali più oggettive. Come riportato in un precedente articolo, per far ciò è possibile andare su “Views” e cliccare su “Intervals and State Machines”. Quindi possiamo cliccare su “Custom Intervals” e generare l’intervallo personalizzato riportato in figura 2.
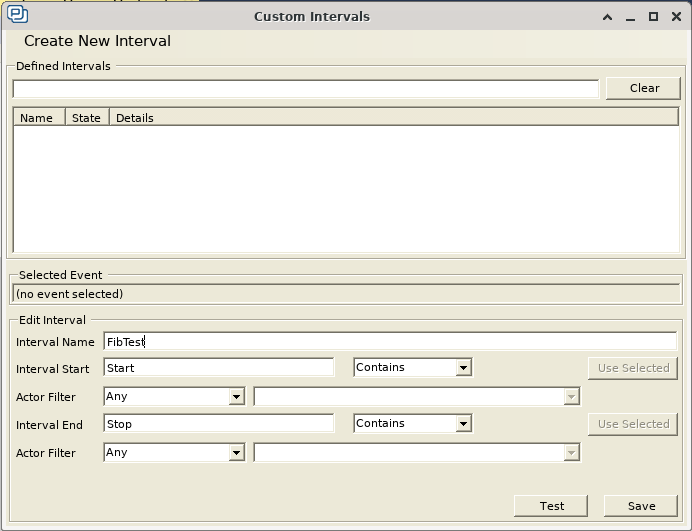
Fig. 2
Abbiamo utilizzato le stringhe “Start” e “Stop” per contrassegnare l’entrata e l’uscita delle funzioni candidate, e così utilizzeremo queste due stringhe per contrassegnare l’inizio e la fine del nostro intervallo personalizzato. Nel momento in cui clicchiamo su “Save”, possiamo vedere che “Trace View” è stato aggiornato con la nuova barra rossa (visibile a destra in figura 3), che identifica il nostro intervallo personalizzato.
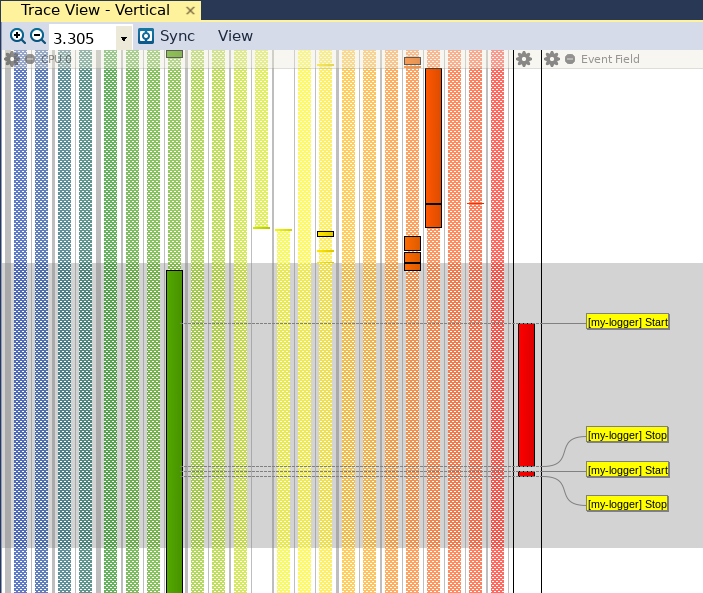
Fig. 3
Quando apriamo la vista “Interval Plot” cliccando su “Views” e quindi su “Interval Plot – Select Set… “ e correggiamo tale vista in modo che nel grafico risultante non venga mostrata alcuna linea, possiamo vedere (fig. 4) che esiste una differenza di un fattore pari a circa 20 in termini di prestazioni tra l’algoritmo ricorsivo (che è stato eseguito per primo) e quello iterativo (eseguito per secondo).
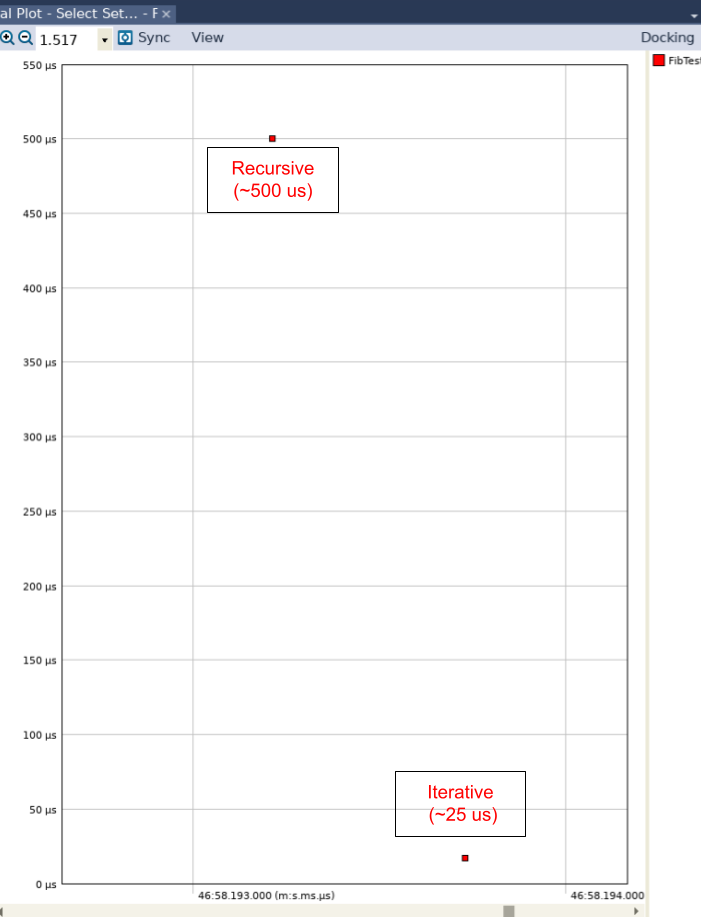
Fig. 4
Abbiamo quindi agevolmente scoperto che in Phython la ricorsione è intrinsecamente più lenta. Tornando alla nostra implementazione in Python, possiamo vedere che abbiamo eseguito solamente 10 iterazioni di ciascun algoritmo. Se non avessimo utilizzato Tracealyzer, avremmo dovuto eseguire un numero molto maggiore di iterazioni per ottenere informazioni significative. Questo approccio risulta comunque problematico per due ragioni. In primo luogo, se l’algoritmo ricorsivo viene eseguito utilizzando un migliaio (o anche un centinaio) di iterazioni, Python semplicemente “si siede” (provare per credere!). Si tratta di un problema di notevole entità per gli sviluppatori, in quanto non è possibile capire se questo sensibile rallentamento sia imputabile a un errore (bug) di implementazione o a una qualsiasi altra causa.
La questione assume una maggiore rilevanza nel momento in cui l’algoritmo o l’implementazione diventano più complessi, poiché sarà necessaria una registrazione più dettagliata per comprendere dov’è il collo di bottiglia. In secondo luogo, se vi sono più applicazioni in esecuzione sul sistema embedded installato, queste potrebbero interrompere la nostra applicazione con un aggravio del tempo richiesto per completare l’esecuzione del nostro algoritmo o funzione. In assenza di un trace, non potremo verificare questo aspetto.
I tracepoint aggiungono un overhead minimo
La combinazione di LTTng in Python e Tracealyzer ci ha permesso di scoprire una caratteristica fondamentale del linguaggio Python di estrema importanza per tutti coloro impegnati nello sviluppo di algoritmi più complessi. Poichè i tracepoint aggiungono un overhead minimo, possiamo mantenerli nella nostra applicazione nel momento in cui la collaudiamo nel nostro sistema target. In questo modo potremo ottenere informazioni dettagliate sulle prestazioni della nostra applicazione mentre altre applicazioni sono in esecuzione.
La nostra implementazione sopra riportata serve anche come modello da seguire per valutare le prestazioni di future implementazioni dell’algoritmo. Come mostrato sopra, abbiamo isolato le funzioni principali in un modulo Phython separato. Non solo ciò rappresenta una buona pratica di programmazione in generale, ma consente anche di concentrare l’attenzione sulle prestazioni di funzioni specifiche. Così come abbiamo creato un modulo Python più completo che effettua chiamate dirette alle funzioni principali, potremmo generare una serie di moduli di test in grado di emettere simili eventi prima di effettuare chiamate alle funzioni sotto test.
Oltre a ciò, poiché l’overhead del trace è quasi trascurabile, possiamo anche generare delle metriche sulle prestazioni nel nostro codice che andrà in produzione. Ciò risulterebbe estremamente utile per effettuare un test regolare del sistema, dove il medesimo codebase può essere utilizzato per garantire che l’applicazione sia corretta dal punto di vista funzionale e garantisca le prestazioni richieste con modifiche veramente minime.
Considerazioni conclusive
In questo articolo abbiamo dimostrato come utilizzare Tracealyzer e LTTng per acquisire metriche sulle prestazioni in un’applicazione Python. Grazie al minimo overhead, possiamo mantenere l’instrumentazione sul nostro target embedded, il che ci consente di monitorare e comprendere l’interazione che la nostra applicazione ha con altre applicazioni e con il sistema operativo. Ad esempio, un altro processo o thread potrebbe causare l’interruzione (preemption) della nostra applicazione, penalizzandone le prestazioni. Possiamo utilizzare Tracealyzer e LTTng per comprendere la causa di queste prestazioni anomale e migliorare la nostra implementazione al fine di evitarle.
Oltre a ciò, utilizzando un esempio relativamente semplice, abbiamo appreso una caratteristica chiave del linguaggio Python da tenere in considerazione in future e più complesse implementazioni. Abbiamo anche proposto un design idoneo per misurare e validare le prestazioni delle funzioni chiave principali che possono essere mantenute relativamente isolate. Abbiamo infine dimostrato come questo meccanismo possa essere ampliato per assicurare che la nostra applicazione sia funzionalmente corretta e in grado di fornire le prestazioni volute con modifiche minime nel setup.
 Mohammed Billoo, fondatore di MAB Labs, LLC (www.mab-labs.com), può vantare un’esperienza di oltre 12 anni nella definizione di architetture, progettazione, implementazione e collaudo di software embedded, con una particolare enfasi su Linux embedded. La sua attività spazia dal bring-up di schede custom allo sviluppo di driver e di codice applicativo. Mohammed è un attivo contributore per il kernel Linux e partecipa a numerose attività nell’ambito dell’open source.
Mohammed Billoo, fondatore di MAB Labs, LLC (www.mab-labs.com), può vantare un’esperienza di oltre 12 anni nella definizione di architetture, progettazione, implementazione e collaudo di software embedded, con una particolare enfasi su Linux embedded. La sua attività spazia dal bring-up di schede custom allo sviluppo di driver e di codice applicativo. Mohammed è un attivo contributore per il kernel Linux e partecipa a numerose attività nell’ambito dell’open source.
E’ professore aggiunto di Ingegneria Elettrica presso la “Cooper Union for the Advancement of Science and Art” dove insegna ai corsi di Logica digitale, Progettazione e Architetture di Computer.
Mohammed ha conseguito la laurea e il successivo master in Ingegneria Elettrica presso la stessa istituzione.
Contenuti correlati
-
 Percepio presenta la release 4.9 di Tracealyzer
Percepio presenta la release 4.9 di TracealyzerÈ disponibile la versione 4.9 di Tracealyzer, il tool di punta di Percepio per il software embedded. Questa nuova release è focalizzata sul miglioramento dell’esperienza dell’utente con le distribuzioni Linux. L’installazione, infatti, è stata notevolmente semplificata e...
-
 Cinque passi per semplificare il debug di applicazioni multithread
Cinque passi per semplificare il debug di applicazioni multithreadUn’analisi di cinque semplici pratiche che permettono di ricavare le informazioni necessarie sul comportamento real-time a livello di sistema, per migliorare la qualità del prodotto, accelerare lo sviluppo e ridurre il time-to-market Leggi l’articolo completo su Embedded...
-
 Virtualizzazione e monitoraggio remoto: un valido approccio per affrontare i problemi nella catena di approvvigionamento
Virtualizzazione e monitoraggio remoto: un valido approccio per affrontare i problemi nella catena di approvvigionamentoDevAlert Sandbox di Percepio è un esempio di come la virtualizzazione e l’emulazione hardware possano essere integrate in un package compatto, consentendo alle aziende che sviluppano prodotti edge/IoT di continuare a farlo senza dover attendere la disponibilità...
-
 Disponibile la versione 4.7 di Percepio Tracealyzer
Disponibile la versione 4.7 di Percepio TracealyzerPercepio ha annunciato la disponibilità della versione 4.7 di Tracealyzer che aggiunge numerose nuove funzionalità e significativi miglioramenti per gli sviluppatori. Tra le novità, per esempio, ci sono l’osservabilità di qualsiasi software C/C++ e il supporto per...
-
 Percepio presenta DevAlert Sandbox
Percepio presenta DevAlert SandboxPercepio ha rilasciato DevAlert Sandbox, una piattaforma online “pronta all’uso” per DevAlert, il framework di monitoraggio per il rilevamento da remoto di anomalie e il debug di software basato su RTOS. “In un mondo segnato dalla presenza...
-
Comprendere l’impatto delle opzioni di compilazione sulle prestazioni
Nel precedente articolo abbiamo discusso come utilizzare LTTng per instrumentare le applicazioni in spazio utente e visualizzare i dati di trace in Tracealyzer a scopo di indagine. In questo articolo capiremo come l’abbinamento di LTTng e Tracealyzer...
-
 Percepio migliora il supporto per Zephyr e ThreadX in Tracealyzer 4.6
Percepio migliora il supporto per Zephyr e ThreadX in Tracealyzer 4.6Percepio ha rilasciato Tracealyzer 4.6 con supporto per l’RTOS Zephyr e Azure RTOS ThreadX di Microsoft. Questa nuova versione include anche la libreria di trace di nuova generazione di Percepio con supporto migliorato per il tracing in...
-
 Utilizzo di Tracealyzer per Linux per valutare le prestazioni in spazio utente
Utilizzo di Tracealyzer per Linux per valutare le prestazioni in spazio utenteMohammed Billoo, fondatore di MAB Labs (www.mab-labs.com), fornisce soluzioni Linux embedded per una vasta gamma di piattaforme hardware. In questa serie di articoli Billoo ci guida attraverso il supporto di Tracealyzer v. 4.4 per Linux utilizzando come...
-
Valutare le prestazioni di un sistema Linux mediante Tracealyzer
Quando si sviluppa un’applicazione basata su Linux, è importante configurare il sistema in modo da ottimizzare le prestazioni poichè una configurazione non idonea potrebbe penalizzare le prestazioni dell’applicazione stessa. Personalmente ho fatto parte di un team coinvolto...
-
 Utilizzo dei tool di trace in ambiente Linux
Utilizzo dei tool di trace in ambiente LinuxMohammed Billoo, fondatore di MAB Labs, una realtà specializzata nel fornire servizi di ingegnerizzazione di software embedded, utilizza Linux embedded su una molteplicità di piattaforme hardware. Billoo ha valutato in che modo il nuovo supporto di Percepio...
Scopri le novità scelte per te
-
Percepio presenta la release 4.9 di Tracealyzer
È disponibile la versione 4.9 di Tracealyzer, il tool di punta di Percepio per il software embedded....
-
Cinque passi per semplificare il debug di applicazioni multithread
Un’analisi di cinque semplici pratiche che permettono di ricavare le informazioni necessarie sul comportamento real-time a livello...

News/Analysis Tutti ▶
-
 Samtec premia Mouser Electronics
Samtec premia Mouser ElectronicsMouser Electronics ha annunciato di aver ricevuto il premio Global High Service Distributor of...
-
 I nuovi induttori di Chemi-Con da TTI
I nuovi induttori di Chemi-Con da TTITTI IP&E – Europe ha comunicato la disponibilità della serie FW di induttori del...
-
 Da Rutronik un display rotondo personalizzabile
Da Rutronik un display rotondo personalizzabileRutronik ha aggiunto alla sua offerta di display il modello DLC0210RHCS-1 di DLC Displays....
Products Tutti ▶
-
I nuovi induttori di Chemi-Con da TTI
TTI IP&E – Europe ha comunicato la disponibilità della serie FW di induttori del...
-
 Infineon presenta i microntrollori PSOC Control
Infineon presenta i microntrollori PSOC ControlInfineon Technologies ha annunciato la disponibilità di PSOC Control, una nuova famiglia di microcontrollori...
-
Da Rutronik un display rotondo personalizzabile
Rutronik ha aggiunto alla sua offerta di display il modello DLC0210RHCS-1 di DLC Displays....

{kind=link}