Comprendere l’impatto delle opzioni di compilazione sulle prestazioni
-

- Tweet
- Pin It
- Condividi per email
-
Nel precedente articolo abbiamo discusso come utilizzare LTTng per instrumentare le applicazioni in spazio utente e visualizzare i dati di trace in Tracealyzer a scopo di indagine. In questo articolo capiremo come l’abbinamento di LTTng e Tracealyzer permetta di evidenziare immediatamente in che modo le opzioni di compilazione influenzino le prestazioni, un compito tradizionalmente invasivo e relativamente difficile da espletare.
In questo articolo vedremo come le opzioni di compilazione in virgola mobile possano influenzare le prestazioni anche dei calcoli più semplici, come il calcolo del seno trigonometrico di un angolo. Da questo esperimento, saremo in grado di capire come queste opzioni possano influenzare le prestazioni delle applicazioni dello spazio utente che stanno eseguendo calcoli più complessi.
Questo è lo snippet (frammento di codice sorgente) che è alla base di questo esperimento:
| #include <math.h>
#include <lttng/tracef.h>
int main(int argc, char *argv[]) { int x; float sample_freq = 1000; float freq = 100; float sample; float t;
for (t = 0; t < 1000; t++) { sample = sin((2*M_PI*freq*t)/sample_freq); tracef(“%f”, sample); }
return 0; } |
Con questo snippet stiamo calcolando 1.000 punti di un’onda sinusoidale a una frequenza di 100 Hz campionati a 1 kHz.
Di seguito viene riportato il Makefile che abbiamo usato per realizzare lo snippet di codice appena sopra riportato, che è molto semplice:
| .PHONY: all
all: hello
sine_test: sine_test.o ${CC} -o sine_test sine_test.o -llttng-ust -ldl -lm
sine_test.o: sine_test.c ${CC} -c sine_test.c |
A questo punto avviamo una sessione di LTTng, eseguiamo il codice binario compilato in riga di comando e terminiamo la sessione (in un precedente articolo abbiamo spiegato come fare). A questo punto, trasferiamo il trace sul nostro PC, lo apriamo in Tracealyzer, configuriamo la User Event Interpretation e vedremo il grafico riportato in figura 1 nella vista User Event Signal Plot.
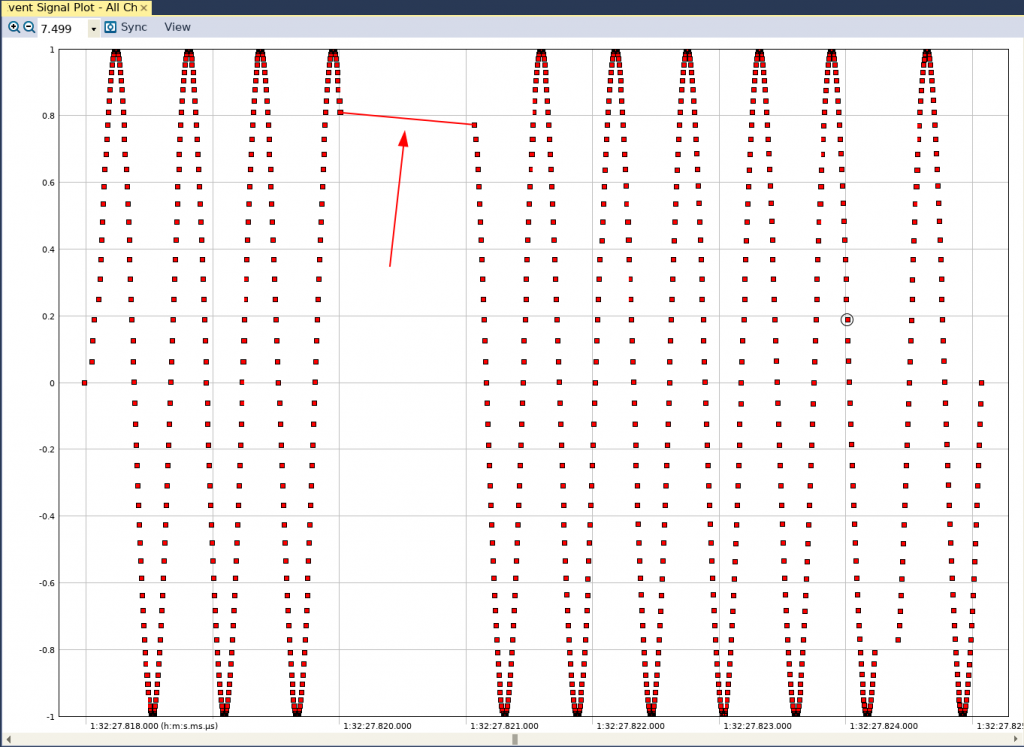
Fig. 1
Dall’esame della figura si può notare una discontinuità nella forma d’onda sinusoidale (evidenziata dalla linea rossa). Nel caso aggiungessimo una chiamata printf al nostro snippet di codice per stampare ogni campione su file e riportare graficamente i contenuti del file, otterremmo l’andamento riportato in figura 2.
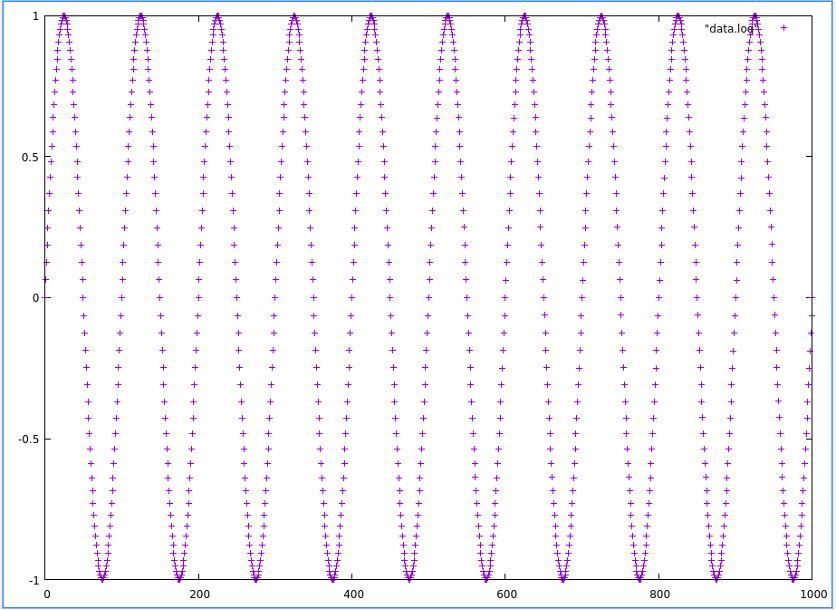
Fig.2
La figura 2 riporta un’onda sinusoidale regolare senza alcune segno di discontinuità. Ciò deriva dal fatto che quando stampiamo i valori su file non esiste il concetto di tempo. Stiamo semplicemente esportando i valori calcolati in funzione del conteggio dei campioni. Tuttavia, quando forniamo i valori calcolati al file di trace, il tempo del sistema è incluso con ogni valore del trace.
Ora aggiorniamo Makefile per aggiungere un’opzione di compilazione e osserviamo i risultati (queste opzioni saranno discusse più dettagliatamente nella parte finale di questo articolo).
| .PHONY: all
all: hello
sine_test: sine_test.o ${CC} -o sine_test sine_test.o -llttng-ust -ldl -lm
sine_test.o: sine_test.c -mfloat-abi=hard |
Se acquisiamo ancora un altro trace, nella vista User Event Single Plot vedremo l’andamento riportato in figure 3.
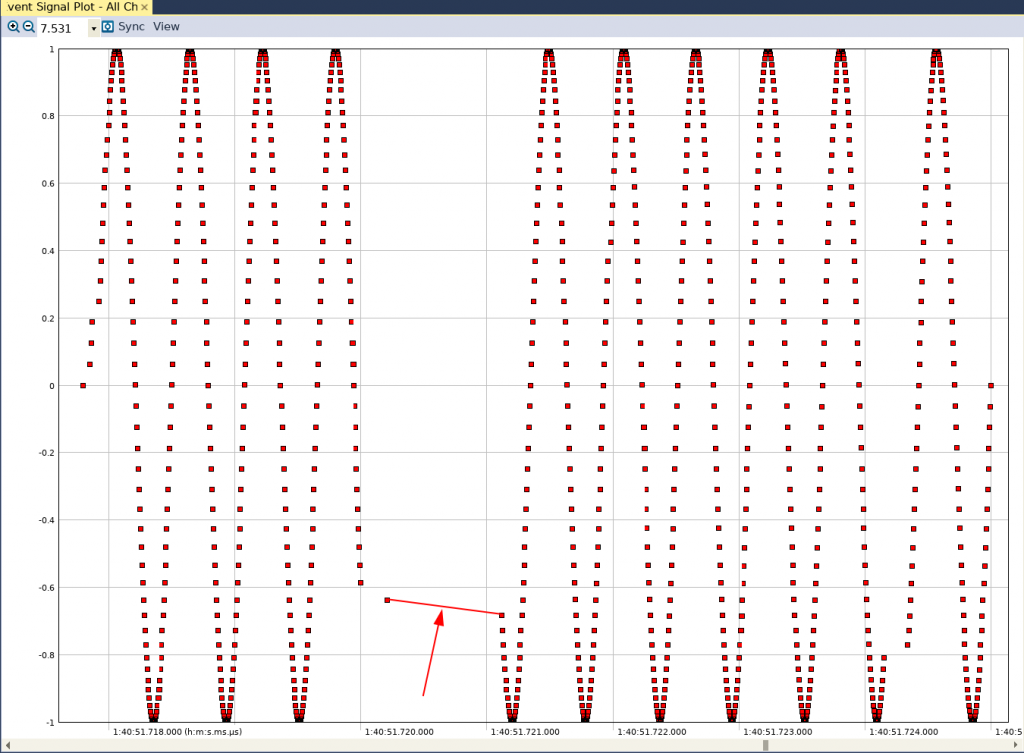
Fig. 3
La discontinuità è ancora visibile. Aggiorniamo ancora Makefile per aggiungere un’altra opzione di compilazione.
| .PHONY: all
all: hello
sine_test: sine_test.o ${CC} -o sine_test sine_test.o -llttng-ust -ldl -lm
sine_test.o: sine_test.c -mfloat-abi=hard -mfpu=neon |
Il grafico nella vista User Event Signal Plot di questo trace, acquisito con la funzione fpu abilitata, in Tracealyzer avrà l’andamento riportato in figura 4.
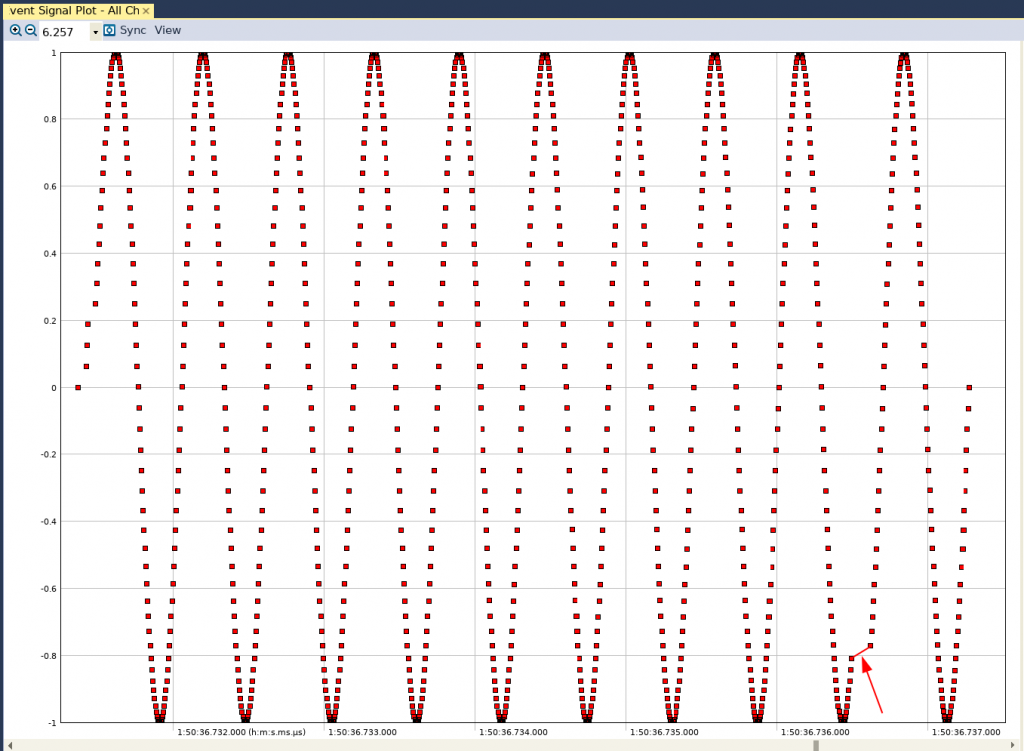
Fig. 4
In questo caso, anche se è sempre presente una discontinuità nella forma d’onda risultante, possiamo osservare che l’intervallo di tempo si è ridotto in maniera significativa (è bene tener presente che l’intervallo che intercorre tra due punti su questo grafico è un tempo reale).
Emulazione delle operazioni in virgola mobile con istruzioni intere
Discutiamo ora le opzioni di compilazione che sono state aggiunte a Makefile nell’ambito delle operazioni in virgola mobile e i motivi per cui c’è stato un impatto sulle prestazioni. A questo punto è utile ricordare che l’architettura di una CPU standard (come a esempio un processore ARM) è progettata per eseguire in maniera efficiente operazioni su numeri interi. L’architettura di una CPU non è progettata per eseguire in modo efficiente operazioni su numeri in virgola mobile. Quindi cosa accade quando abbiamo codice che esegue operazioni in virgola mobile?
Nel caso del primo Makefile, privo di qualsiasi opzione aggiuntiva, il compilatore converte le istruzioni in virgola mobile che calcolano i valori della sinusoide in una serie di istruzioni basate su interi. Naturalmente ciò comporterà per la CPU l’esecuzione di un numero sensibilmente maggiore di istruzioni. Per tale motivo aumenta la possibilità che i calcoli dell’onda sinusoidale vengano interrotti per consentire l’esecuzione di un altro processo (task) del sistema (pre-emption).
A conferma che ciò sia quanto realmente successo, è sufficiente esaminare la vista Trace View in Tracealyzer (fig. 5). Possiamo vedere che il processo responsabile dei calcoli dell’onda sinusoidale viene interrotto da altri processi. Possiamo anche notare che questo particolare processo è sospeso una volta per 900 microsecondi.
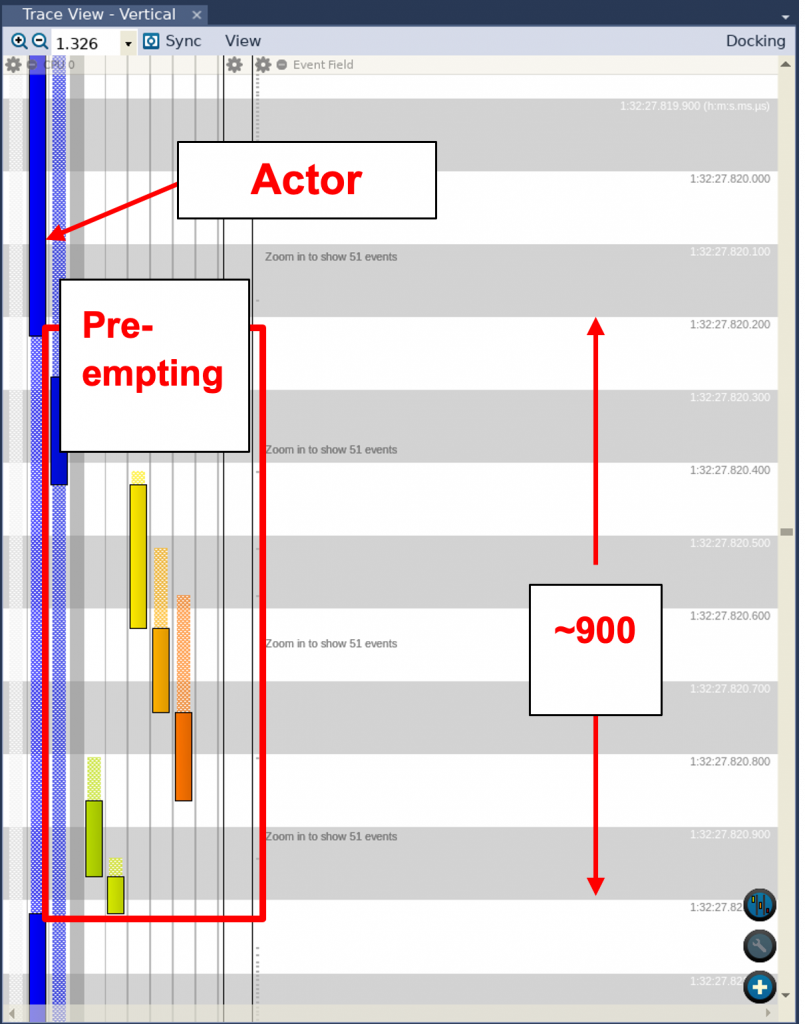
Fig.5
Quando abbiamo specificato l’opzione “-mfloat-abi=hard” nel secondo Makefile, abbiamo dato istruzione al compilatore di utilizzare un set di istruzioni espressamente progettato per le operazioni in virgola mobile. Tuttavia, non ha prodotto alcuna reale differenza nel risultato, in quanto abbiamo rilevato un’analoga discontinuità. A conferma di ciò, osservando la vista Trace View relativa al secondo trace (Fig. 6), si può vedere che il processo del calcolo dell’onda sinusoidale è stato sospeso per lo stesso periodo di tempo, ovvero 900 microsecondi.

Fig.6
Come si spiega questo fatto? All’interno di questo set di istruzioni in virgola mobile vi sono estensioni specifiche che abilitano un’unità in virgola mobile (FPU) ottimizzata integrata nel processore stesso. Tuttavia, se non specifichiamo l’opzione “fpu” per il compilatore, quest’ultimo non utilizza l’opzione per cui le istruzioni in virgola mobile saranno ancora emulate utilizzando le istruzioni intere standard.
Aggiungendo l’opzione “-mfpu=neon”, come è stato fatto nella terza esecuzione, viene impartita al compilatore l’istruzione di abilitare uno specifico set di estensioni per questa particolare FPU (NEON). Poichè la maggior parte dei calcoli in virgola mobile viene eseguita su un coprocessore separato, le possibilità che altri processi interrompano la generazione della forma d’onda sono alquanto scarse: da qui la discontinuità molto più contenuta osservata nella vista User Event Signal Plot.
Un’altra possibilità: intervalli personalizzati
Ma c’è di più: possiamo anche visualizzare il periodo di tempo richiesto da ciascun calcolo della sinusoide in Tracealyzer utilizzando gli intervalli personalizzati (Custom Intervals). Per fare ciò, eliminiamo l’invocazione di tracef con i valori della sinusoide calcolati e inseriamo il tracing degli eventi dell’utente “Start” e “Stop” (in maniera del tutto analoga a quella spiegata in un precedente articolo).
| .
. . for (t = 0; t < 1000; t++) { tracef(“Start”); sample = sin((2*M_PI*freq*t)/sample_freq); tracef(“Stop”); } . . |
A questo punto compiliamo ed eseguiamo l’applicazione con le variazioni sopra indicate, senza usare l’opzione di compilazione “float_abi=hard” e generiamo i dati di trace. Possiamo quindi visualizzare i dati di trace in Tracealyzer, configurare un intervallo custom, aprire la vista Interval Timeline che mostrerà ciò che è riportato in figure 7 (vista del trace a sinistra, vista degli intervalli a destra).
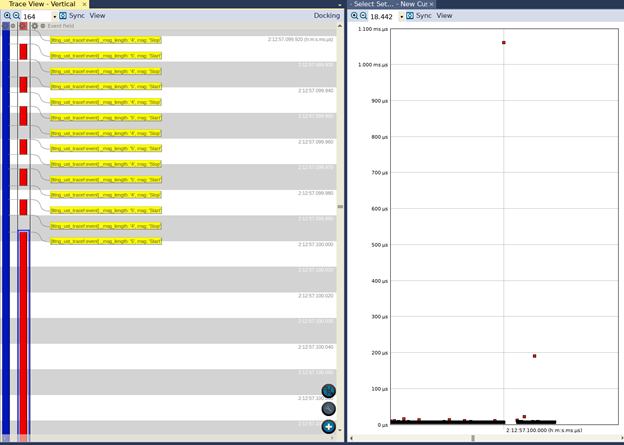
Fig. 7
Possiamo vedere che, mentre generalmente l’esecuzione della funzione richieda tempi dell’ordine delle decine di microsecondi, vi sono alcuni valori anomali. In un caso l’esecuzione della funzione richiede all’incirca 200 microsecondi, mentre in un altro caso sono necessari circa 1,05 millisecondi!
Se eseguiamo le medesime operazioni dopo aver aggiunto l’opzione ABI hard (ma non le estensioni NEON), nella vista Interval Timeline vedremo ciò che è riportato nella figura 8.
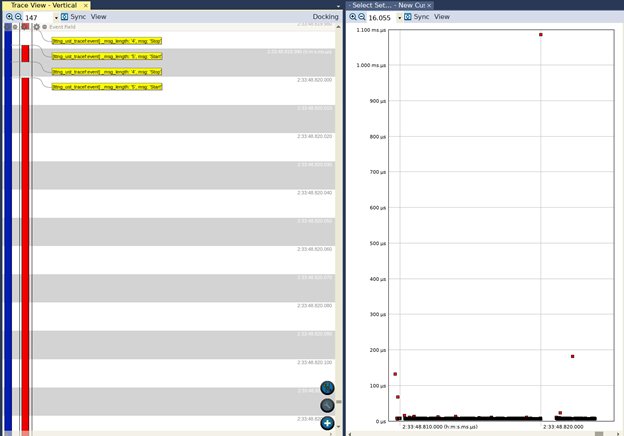
Fig. 8
Ancora una volta osserviamo un comportamento simile a quello riscontrato utilizzando l’ABI soft. Mentre la maggior parte delle esecuzioni richiede tempi dell’ordine delle decine di microsecondi, vi sono alcuni valori anomali compresi tra 100 e 200 microsecondi. Possiamo anche vedere un’invocazione che richiede quasi 1,1 millisecondi!.
Infine, se apriamo un trace acquisito quando l’applicazione è stata compilata per utilizzare sia l’ABI hard sia le estensioni NEON, vedremo ciò che è rappresentato in figura 9.
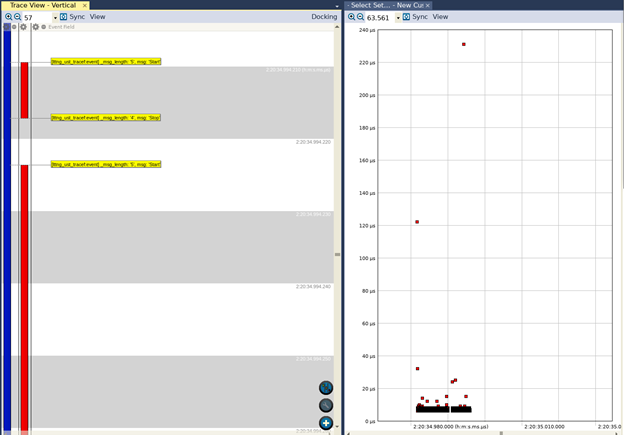
Fig. 9
In questo caso, anche se vi sono ancora alcuni valori anomali, possiamo vedere che il tempo di esecuzione più lungo è di poco inferiore a 240 microsecondi. Ciò a conferma dell’affermazione fatta in precedenza, ovvero che l’aggiunta delle estensioni NEON riduce considerevolmente il ritardo tra i punti di calcolo nel caso peggiore (worst case).
In conclusione, siamo stati in grado di sfruttare la libreria di LTTng e Tracealyzer per comprendere in breve tempo l’impatto di determinate opzioni di compilazione sulle prestazioni delle applicazioni dello spazio utente che eseguono calcoli in virgola mobile. Solitamente un’analisi di questo tipo viene fatta a posteriori, quando l’applicazione è completata ma le prestazioni osservate sono considerate non accettabili, e richiede tempi lunghi. L’utilizzo di Tracealyzer durante lo sviluppo per verificare la temporizzazione del software ha permesso di evitare una situazione di questo tipo.
Informazione sull’autore
 Mohammed Billoo, fondatore di MAB Labs, LLC (www.mab-labs.com), può vantare un’esperienza di oltre 12 anni nella definizione di architetture, progettazione, implementazione e collaudo di software embedded, con una particolare enfasi su Linux embedded. LA sua attività spazia dal bring-up di schede custom alla scrittura di software per driver di dispositivi custom e di codice applicativo. Mohammed è un attivo contributore per il kernel Linux e partecipa a numerose attività nell’ambito dell’open source. E’ professore aggiunto di Ingegneria Elettrica presso la “Cooper Union for the Advancement of Science and Art” dove insegna ai corsi di Logica digitale, Progettazione e Architetture di Computer.
Mohammed Billoo, fondatore di MAB Labs, LLC (www.mab-labs.com), può vantare un’esperienza di oltre 12 anni nella definizione di architetture, progettazione, implementazione e collaudo di software embedded, con una particolare enfasi su Linux embedded. LA sua attività spazia dal bring-up di schede custom alla scrittura di software per driver di dispositivi custom e di codice applicativo. Mohammed è un attivo contributore per il kernel Linux e partecipa a numerose attività nell’ambito dell’open source. E’ professore aggiunto di Ingegneria Elettrica presso la “Cooper Union for the Advancement of Science and Art” dove insegna ai corsi di Logica digitale, Progettazione e Architetture di Computer.
Mohammed ha conseguito la laurea e il successivo master in Ingegneria Elettrica presso la stessa istituzione.
Contenuti correlati
-
 Percepio presenta la release 4.9 di Tracealyzer
Percepio presenta la release 4.9 di TracealyzerÈ disponibile la versione 4.9 di Tracealyzer, il tool di punta di Percepio per il software embedded. Questa nuova release è focalizzata sul miglioramento dell’esperienza dell’utente con le distribuzioni Linux. L’installazione, infatti, è stata notevolmente semplificata e...
-
 Cinque passi per semplificare il debug di applicazioni multithread
Cinque passi per semplificare il debug di applicazioni multithreadUn’analisi di cinque semplici pratiche che permettono di ricavare le informazioni necessarie sul comportamento real-time a livello di sistema, per migliorare la qualità del prodotto, accelerare lo sviluppo e ridurre il time-to-market Leggi l’articolo completo su Embedded...
-
 Virtualizzazione e monitoraggio remoto: un valido approccio per affrontare i problemi nella catena di approvvigionamento
Virtualizzazione e monitoraggio remoto: un valido approccio per affrontare i problemi nella catena di approvvigionamentoDevAlert Sandbox di Percepio è un esempio di come la virtualizzazione e l’emulazione hardware possano essere integrate in un package compatto, consentendo alle aziende che sviluppano prodotti edge/IoT di continuare a farlo senza dover attendere la disponibilità...
-
 Disponibile la versione 4.7 di Percepio Tracealyzer
Disponibile la versione 4.7 di Percepio TracealyzerPercepio ha annunciato la disponibilità della versione 4.7 di Tracealyzer che aggiunge numerose nuove funzionalità e significativi miglioramenti per gli sviluppatori. Tra le novità, per esempio, ci sono l’osservabilità di qualsiasi software C/C++ e il supporto per...
-
 Un’interfaccia aperta per una diagnostica dei veicoli più efficiente
Un’interfaccia aperta per una diagnostica dei veicoli più efficienteHella Gutmann, una delle più importanti aziende nel settore della diagnostica dei veicoli, ha deciso di sfruttare il know-how acquisito da Kontron per tenere il passo con l’evoluzione dei requisiti di comunicazione delle principali Case automobilistiche Leggi l’articolo...
-
 Percepio presenta DevAlert Sandbox
Percepio presenta DevAlert SandboxPercepio ha rilasciato DevAlert Sandbox, una piattaforma online “pronta all’uso” per DevAlert, il framework di monitoraggio per il rilevamento da remoto di anomalie e il debug di software basato su RTOS. “In un mondo segnato dalla presenza...
-
 Utilizzo di Tracealyzer per valutare gli algoritmi di Python in Linux
Utilizzo di Tracealyzer per valutare gli algoritmi di Python in LinuxMohammed Billoo, fondatore di MAB Labs (www.mab-labs.com), fornisce soluzioni Linux embedded per una vasta gamma di piattaforme hardware. In questa serie di articoli Billoo ci guida attraverso il supporto di Tracealyzer v. 4.4 per Linux In un...
-
 Percepio migliora il supporto per Zephyr e ThreadX in Tracealyzer 4.6
Percepio migliora il supporto per Zephyr e ThreadX in Tracealyzer 4.6Percepio ha rilasciato Tracealyzer 4.6 con supporto per l’RTOS Zephyr e Azure RTOS ThreadX di Microsoft. Questa nuova versione include anche la libreria di trace di nuova generazione di Percepio con supporto migliorato per il tracing in...
-
Utilizzo di Tracealyzer per Linux per valutare le prestazioni in spazio utente
Mohammed Billoo, fondatore di MAB Labs (www.mab-labs.com), fornisce soluzioni Linux embedded per una vasta gamma di piattaforme hardware. In questa serie di articoli Billoo ci guida attraverso il supporto di Tracealyzer v. 4.4 per Linux utilizzando come...
-
Valutare le prestazioni di un sistema Linux mediante Tracealyzer
Quando si sviluppa un’applicazione basata su Linux, è importante configurare il sistema in modo da ottimizzare le prestazioni poichè una configurazione non idonea potrebbe penalizzare le prestazioni dell’applicazione stessa. Personalmente ho fatto parte di un team coinvolto...
Scopri le novità scelte per te
-
Percepio presenta la release 4.9 di Tracealyzer
È disponibile la versione 4.9 di Tracealyzer, il tool di punta di Percepio per il software embedded....
-
Cinque passi per semplificare il debug di applicazioni multithread
Un’analisi di cinque semplici pratiche che permettono di ricavare le informazioni necessarie sul comportamento real-time a livello...

News/Analysis Tutti ▶
-
 congatec compie 20 anni
congatec compie 20 annicongatec ha recentemente celebrato il suo ventesimo anniversario. Coerentemente con la propria visione, l’azienda...
-
 Partnership tra Advantech e ADATA per gli AMR
Partnership tra Advantech e ADATA per gli AMRAdvantech ha annunciato una partnership con ADATA per lo sviluppo di un robot mobile...
-
 La connettività in ambienti difficili analizzata in un eBook di Mouser e Cinch
La connettività in ambienti difficili analizzata in un eBook di Mouser e CinchMouser Electronics, in collaborazione con Cinch Connectivity Solutions, ha pubblicato un nuovo eBook intitolato...
Products Tutti ▶
-
 Un nuovo touch controller da Microchip
Un nuovo touch controller da MicrochipMTCH2120 è un nuovo touch controller a 12 pulsanti di Microchip Technology. Questo componente,...
-
 Panasonic Industry annuncia un nuova serie di relè
Panasonic Industry annuncia un nuova serie di relèPanasonic Industry ha recentemente presentato un nuovo relè PhotoMOS progettato per apparecchiature di misurazione,...
-
 Panasonic migliora la produzione di PCB
Panasonic migliora la produzione di PCBPanasonic Connect Europe ha realizzato il nuovo modular mounter NPM-GW, un modulo di montaggio...