Utilizzo di Tracealyzer per Linux per valutare le prestazioni in spazio utente
-

- Tweet
- Pin It
- Condividi per email
-
Mohammed Billoo, fondatore di MAB Labs (www.mab-labs.com), fornisce soluzioni Linux embedded per una vasta gamma di piattaforme hardware. In questa serie di articoli Billoo ci guida attraverso il supporto di Tracealyzer v. 4.4 per Linux utilizzando come esempio un progetto reale.
Nei precedenti articoli abbiamo analizzato un sistema embedded mediante il tracing degli eventi del kernel Linux. Se è importante assicurare che qualsiasi personalizzazione del kernel Linux, compresi i driver del dispositivo, sia corretta e assicuri le prestazioni desiderate, probabilmente è ancora più importante per gli utenti validare le loro proprie applicazioni in userspace e assicurare che le prestazioni siano quelle previste.
La maggior parte degli sviluppatori di software per Linux embedded scrive le applicazioni in spazio utente. Poichè tali applicazioni sono specifiche di un determinato dominio e sono generalmente complesse, gli sviluppatori hanno bisogno di un meccanismo semplice per validare la funzionalità delle loro applicazioni e misurarne le prestazioni. In questo articolo verrà mostrato come creare punti di tracciamento (tracepoint) di LTTng e come utilizzare Tracealyzer per Linux per misurare determinate metriche sulla base di questi tracepoint. Questa volta ci focalizzeremo sui linguaggi C/C++, mentre in un prossimo articolo verranno illustrati principi simili in Python.
I tracepoint sono i punti di misura (instrumentation point) forniti da LTTng-UST (ovvero la libreria di tracing dello spazio utente di LTTng) che fondamentalmente acquisiscono i dati specificati dall’utente come eventi. I tracepoint possono essere creati in due modi: il primo, denominato tracef, è un metodo molto semplice per acquisire tutti i dati come un singolo evento. Il secondo consente a uno sviluppatore di creare eventi personalizzati. Sebbene quest’ultimo meccanismo richieda molto più codice, garantisce la massima flessibilità per la raccolta dei dati e la loro visualizzazione in Tracelyzer.
In questo articolo utilizzeremo la tecnica tracef, mentre gli eventi personalizzati verranno trattati in un prossimo articolo. Come appena menzionato, tracef è molto semplice; il seguente snippet (frammento di codice sorgente) mostra come aggiungere il tracing all’esempio “Hello World”:
#include <lttng/tracef.h>
int main(void)
{
int i;
for (i = 0; i < 25; i++)
{
tracef(“Hello World: %d”, i);
}
return 0;
}
Le linee in grassetto sono tutto ciò che serve per registrare (log) un evento nello spazio utente di LLTng: includono il file di intestazione (header) appropriato e la chiamata a tracef per emettere un evento in spazio utente, in modo simile a quello di una classica funzione print(f).
Accertarsi che LTTng sia installato
Per prima cosa è necessario accertarsi che LTTng sia installato sulla nostra piattaforma target, utilizzando passaggi simili a quelli illustrati nel primo articolo di questa serie. Successivamente bisogna eseguire la cross-compilazione dello snippet sopra riportato ed eseguire i seguenti comandi sulla piattaforma target per acquisire i dati di trace in modo da poterli visualizzare in Tracealyzer.
lttng create
lttng enable-event -k sched_*
lttng add-context -k -t pid
lttng add-context -k -t ppid
lttng enable-event -u ‘lttng_ust_tracef:*’
lttng add-context -u -t vtid
lttng start
<run the userspace application>
lttng stop
lttng destroy
Gli elementi in grassetto sono i più rilevanti perchè consentono di acquisire i dati in spazio utente ed eseguire l’applicazione.
Un altro punto interessante è il fatto che, sulla base dei precedenti comandi, stiamo anche acquisendo trace del kernel e ci si potrebbe chiedere il motivo di questa operazione. Le ragioni sono due. In primo luogo, il trace del kernel incluso potrebbe spiegare la sequenza temporale degli eventi in spazio utente. Per esempio, se otteniamo un ritardo prolungato tra due eventi nella nostra applicazione, gli eventi del kernel dovrebbero consentirci di vedere la causa del ritardo. In secondo luogo, a partire dalla versione 4.4.2, Tracealyzer richiede alcuni dati del trace del kernel per visualizzare correttamente gli eventi UST, sebbene non sia necessario il trace completo del kernel. Il team di Percepio è consapevole di ciò e sta sviluppando una soluzione da implementare nella prossima release.
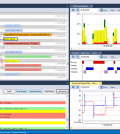
Una volta generata un’acquisizione, il passo successivo è aprirla in Tracealyer per Linux. Dopo aver aperto il trace, la prima cosa da fare è istruire Tracealyzer su come eseguire il parsing (analisi sintattica) e visualizzare gli eventi in spazio utente. Per far ciò è sufficiente selezionare Trace nel menù in alto e cliccare su Configure Event Interpretations (Fig. 1).

Fig. 1
Nella finestra risultante, evidenziate lttng_ust_tracef:event nella colonna Channel Name e cliccate sul tasto Change. Nella finestra successiva che appare, cliccate sul pulsante di scelta User Event Mapping e quindi su Next per arrivare alla seguente schermata di configurazione (Fig. 2).

Fig. 2
La seconda colonna, denominata Data Type, è il tipo di dati di ciascun campo fornito da LTTng. La terza colonna, denominata Cast to Type, consente di convertire, se necessario, il tipo di dati. Per esempio, se qualche tracepoint dello spazio utente volesse registrare un valore numerico come una stringa, la colonna Cast to Type consente di analizzare la stringa come un numero intero. In tal caso, possiamo utilizzare il valore intero nelle visualizzazioni di Tracealyzer, come nello User Event Signal Plot. Il casting, tuttavia, richiede una stringa puramente numerica, per cui non può essere utilizzata in questo caso. Lasciamo quindi la mappatura (mapping) inalterata e lasciamo a Tracealyzer il compito di tracciare la lunghezza del messaggio per dimostrare questa possibilità. Esistono modi migliori per registrare valori numerici con LLTng-UST come sarà dimostrato in un prossimo articolo.
Se lasciamo le colonne inalterate e clicchiamo su Next, poi ancora su Next nella finestra successiva e quindi su Finish nella finestra finale, ritorniamo sulla finestra principale Event Interpretation: in questa finestra possiamo cliccare su Apply and Reload Trace. Una volta che Tracealyzer ha ricaricato il trace, si può iniziare a lavorare. A questo punto bisogna aprire la vista User Event Signal Plot cliccando sul pulsante User Event presente nell’elenco delle icone a sinistra.
Misura delle prestazioni
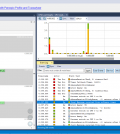
Nella vista “User Event Signal Plot” sembrano esserci solamente due punti di dati, anche se abbiamo chiamato tracef 25 volte. Un ingrandimento rivela la presenza di più punti, mentre un ulteriore ingrandimento ci permette di visualizzare tutte le 25 invocazioni della funzione tracef. Si noti che il valore (sull’asse Y) aumenta dopo 10 invocazioni, poichè la lunghezza della stringa aumenta di un carattere. Nel momento in cui si cliccherà su un punto (immagine a destra di figura 3), Tracealyzer evidenzierà la corrispondente invocazione in Trace View (immagine a sinistra di figura 3).

Fig. 3
Ora cercheremo di utilizzare Tracealyzer per misurare le prestazioni di un’applicazione in spazio utente. In questo specifico esempio, simuleremo una funzione che consuma un certo periodo di tempo con la funzione Linux usleep. Aggiungeremo un tracepoint prima dell’invocazione della funzione e un altro dopo l’invocazione per misurare il tempo necessario al completamento della funzione.
#include <stdlib.h>
#include <unistd.h>
#include <lttng/tracef.h>
int main(void)
{
int i;
for (i = 0; i < 25; i++)
{
tracef(“Start: %d”, i);
usleep(25000);
tracef(“Stop: %d”, i);
}
return 0;
}
In uno scenario reale identificheremo le posizioni della nostra applicazione in corrispondenza delle quali dovremo misurare il tempo di esecuzione e in tali posizioni aggiungeremo le invocazioni tracef. Una funzione, a esempio, potrebbe essere implementata in più modi e noi vogliamo valutarne le tempistiche di esecuzione allo scopo di individuare l’algoritmo più veloce. Oppure, nel caso di una funzione complessa, vogliamo caratterizzare la sua esecuzione.
Dopo aver compilato l’applicazione di cui sopra, lanciato una sessione di LTTng sul target, acquisito e scaricato i dati di trace risultanti, possiamo aprire questi ultimi in Tracealyzer. Se impostiamo il filtro in modo da mostrare solamente gli eventi della nostra applicazione (demo2-sleep) ed eseguiamo un ingrandimento su Trace View, possiamo vedere il familiare evento di trace (fig. 4).
 Fig. 4
Fig. 4
Ora misureremo il tempo di esecuzione delle chiamate della funzione usleep, che in questo caso può essere definito come il tempo che intercorre tra ogni coppia di eventi Start e Stop. Il modo migliore per fare ciò è creare intervalli (Intervals) per il nostro User Event personalizzato. A tal fine selezioniamo “Intervals and State Machine” nel menu Views. Nella finestra che si apre, cliccando su “Custom Intervals” arriveremo alla finestra di configurazione degli intervalli personalizzati dove potremo definire un nuovo data set formato da intervalli tra gli eventi selezionati. Ciò consentirà di estrarre informazioni di temporizzazione dei punti chiave della nostra applicazione.
Definizione dell’intervallo personalizzato
Poiché in Tracealyzer un intervallo è definito da due eventi, ovvero i suoi eventi Start e Stop, creeremo un intervallo che inizi in corrispondenza dell’evento che contiene la stringa Start e finisca in corrispondenza dell’evento che contiene la stringa Stop. Per far ciò, inseriremo le seguenti informazioni in questa finestra (Fig. 5):
- Nome dell’intervallo: Sleep Trace Time Measurement
- Inizio dell’intervallo: Start
- Fine dell’intervallo: Stop
 Fig. 5
Fig. 5
I campi “Actor Filter” ci consentirebbero di specificare un determinato thread, ma in questo caso non è necessario. Un ultimo click sul pulsante Test ci informerà che Tracealyzer è in grado di individuare alcuni intervalli nei dati di trace che corrispondono alle condizioni specificate.
Dopo aver salvato la definizione di intervalli personalizzati, possiamo vedere che essa appare nella finestra “Intervals and State Machine” e che Tracealyzer l’ha evidenziata in Trace View. A questo punto possiamo rappresentare graficamente questo intervallo di temporizzazione, in modo del tutto analogo a quello utilizzato per rappresentare il tempo di esecuzione degli attori nel grafico Actor Istance descritto in un precedente articolo. Per far ciò, andiamo sul menu Views e selezioniamo “Interval Plot – Select Set ….” (Fig. 6).
 Fig. 6
Fig. 6
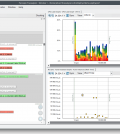
Nella finestra risultante, dopo aver evidenziato il nome del nostro intervallo personalizzato e cliccato su OK, apparirà un nuovo grafico che mostra la durata dei nostri intervalli. E’ possibile apportare piccoli miglioramenti alla visualizzazione grafica per facilitarne la lettura e l’interpretazione (Fig. 7).
- In quella visualizzazione, selezionare il menu View e quindi Line Style – modificarlo con No Lines
- Evidenziare la porzione del grafico contenente i punti risultanti
- Fare click con il pulsante destro del mouse e selezionare Zoom to Selection

Fig. 7
Non può certamente sorprendere il fatto che tutti gli intervalli misurati siano di circa 25 ms
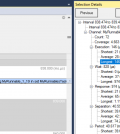
Infine, cliccando su uno di questi punti di dati si possono ottenere utili informazioni di temporizzazione relative al nostro intervallo nella vista Selection Details (Fig. 8).
 Fig. 8
Fig. 8
Il primo box riporta le statistiche relative alla lunghezza di ciascun intervallo, che dovrebbero corrispondere al tempo di esecuzione della funzione di interesse (a meno che il thread non abbia subito la preemption (interruzione dell’esecuzione a causa di una commutazione di contesto, evento che sarebbe comunque visibile nella visualizzazione del trace). Il secondo box mostra le statistiche relative al tempo che intercorre tra le esecuzioni della nostra funzione di interesse (nel nostro caso corrisponderebbe al tempo tra un evento di Stop e il successivo evento di Start). Il terzo box mostra la frequenza con la quale si verifica ciascun intervallo (il tempo che trascorre tra un evento di Start e il successivo.
Interval Plot può essere usato per identificare qualsiasi temporizzazione anomala della funzione di interesse, mentre le informazioni contenute nella visualizzazione Selection Details possono essere impiegate per acquisire statistiche di temporizzazione più approfondite.
Considerazioni conclusive
In definitiva, la maggior parte degli sviluppatori di software embedded svilupperà le applicazioni in spazio utente sui loro sistemi basati su Linux. Tracealyzer, unitamente ai tracepoint di LTTng, può essere uno strumento prezioso per determinare le prestazioni di un’applicazione, identificare qualsiasi comportamento anomalo e fornire statistiche di temporizzazione molto accurate. Tracealyzer può quindi essere utilizzato per individuare e risolvere qualsiasi altro problema di temporizzazione e migliorare così le prestazioni dell’applicazione.
 Informazione sull’autore
Informazione sull’autore
Mohammed Billoo, fondatore di MAB Labs, LLC (www.mab-labs.com), può vantare un’esperienza di oltre 12 anni nella definizione di architetture, progettazione, implementazione e collaudo di software embedded, con una particolare enfasi su Linux embedded. LA sua attività spazia dal bring-up di schede custom alla scrittura di software per driver di dispositivi custom e di codice applicativo. Mohammed è un attivo contributore per il kernel Linux e partecipa a numerose attività nell’ambito dell’open source. E’ professore aggiunto di Ingegneria Elettrica presso la “Cooper Union for the Advancement of Science and Art” dove insegna ai corsi di Logica digitale, Progettazione e Architetture di Computer.
Mohammed ha conseguito la laurea e il successivo master in Ingegneria Elettrica presso la stessa istituzione.
Contenuti correlati
-
 Percepio collabora con BMW Group
Percepio collabora con BMW GroupPercepio ha annunciato una collaborazione con il produttore automobilistico tedesco BMW Group. Il suo prodotto di punta, Tracealyzer, è stato infatti utilizzato da BMW per monitorare e ottimizzare le prestazioni del software nella piattaforma di integrazione IP-Basis...
-
 Disponibile Percepio View per FreeRTOS
Disponibile Percepio View per FreeRTOSPercepio ha rilasciato Percepio View per FreeRTOS, uno strumento di trace gratuito per la diagnostica che offre alla community di sviluppatori FreeRTOS l’osservabilità run-time del sistema. Il tool è disponibile su https://traceviewer.io e su FreeRTOS.org, e consente...
-
 Percepio introduce Percepio Detect
Percepio introduce Percepio DetectPercepio ha annunciato Percepio Detect, uno strumento che offre agli sviluppatori il rilevamento in tempo reale di anomalie e rischi di fragilità del software, insieme a informazioni approfondite e dettagliate utili per il debugging. Lo strumento è...
-
 Percepio presenta la release 4.9 di Tracealyzer
Percepio presenta la release 4.9 di TracealyzerÈ disponibile la versione 4.9 di Tracealyzer, il tool di punta di Percepio per il software embedded. Questa nuova release è focalizzata sul miglioramento dell’esperienza dell’utente con le distribuzioni Linux. L’installazione, infatti, è stata notevolmente semplificata e...
-
 Cinque passi per semplificare il debug di applicazioni multithread
Cinque passi per semplificare il debug di applicazioni multithreadUn’analisi di cinque semplici pratiche che permettono di ricavare le informazioni necessarie sul comportamento real-time a livello di sistema, per migliorare la qualità del prodotto, accelerare lo sviluppo e ridurre il time-to-market Leggi l’articolo completo su Embedded...
-
 Virtualizzazione e monitoraggio remoto: un valido approccio per affrontare i problemi nella catena di approvvigionamento
Virtualizzazione e monitoraggio remoto: un valido approccio per affrontare i problemi nella catena di approvvigionamentoDevAlert Sandbox di Percepio è un esempio di come la virtualizzazione e l’emulazione hardware possano essere integrate in un package compatto, consentendo alle aziende che sviluppano prodotti edge/IoT di continuare a farlo senza dover attendere la disponibilità...
-
 Disponibile la versione 4.7 di Percepio Tracealyzer
Disponibile la versione 4.7 di Percepio TracealyzerPercepio ha annunciato la disponibilità della versione 4.7 di Tracealyzer che aggiunge numerose nuove funzionalità e significativi miglioramenti per gli sviluppatori. Tra le novità, per esempio, ci sono l’osservabilità di qualsiasi software C/C++ e il supporto per...
-
 Un’interfaccia aperta per una diagnostica dei veicoli più efficiente
Un’interfaccia aperta per una diagnostica dei veicoli più efficienteHella Gutmann, una delle più importanti aziende nel settore della diagnostica dei veicoli, ha deciso di sfruttare il know-how acquisito da Kontron per tenere il passo con l’evoluzione dei requisiti di comunicazione delle principali Case automobilistiche Leggi l’articolo...
-
 Percepio to support new PX5 RTOS with Tracealyzer tool
Percepio to support new PX5 RTOS with Tracealyzer toolPercepio AB has teamed up with PX5 to support the launch of a new real-time operating system (RTOS). PX5 has been set up by Bill Lamie, the former chief technology officer of Express Logic and architect of...
-
 Percepio presenta DevAlert Sandbox
Percepio presenta DevAlert SandboxPercepio ha rilasciato DevAlert Sandbox, una piattaforma online “pronta all’uso” per DevAlert, il framework di monitoraggio per il rilevamento da remoto di anomalie e il debug di software basato su RTOS. “In un mondo segnato dalla presenza...
Scopri le novità scelte per te
-
Percepio collabora con BMW Group
Percepio ha annunciato una collaborazione con il produttore automobilistico tedesco BMW Group. Il suo prodotto di punta,...
-
Disponibile Percepio View per FreeRTOS
Percepio ha rilasciato Percepio View per FreeRTOS, uno strumento di trace gratuito per la diagnostica che offre...

News/Analysis Tutti ▶
-
 Le previsioni di TrendForce per le memorie
Le previsioni di TrendForce per le memorieGli analisti di TrendForce indicano che l’attuale tensione nell’approvvigionamento delle memorie diminuirà nella seconda...
-
 Certificazione di sicurezza per i computer Moxa
Certificazione di sicurezza per i computer MoxaI computer Moxa della serie UC basati su architettura Arm a 64 bit che...
-
 Yole Group pubblica un report sul packaging avanzato
Yole Group pubblica un report sul packaging avanzatoYole Group ha pubblicato il report “Status of the Advanced Packaging Industry 2026″ che...
Products Tutti ▶
-
 I nuovi isolatori a stato solido di Infineon
I nuovi isolatori a stato solido di InfineonInfineon ha introdotto una nuova tecnologia per gli isolatori a stato solido (SSI) che...
-
 Amphenol: nuovi connettori compatti
Amphenol: nuovi connettori compattiAmphenol Industrial Operations ha introdotto nella sua offerta di connettori la nuova serie ePower-Lite...
-
 Connettori RF a 30 gradi da Samtec
Connettori RF a 30 gradi da SamtecSamtec ha annunciato la disponibilità del nuovo connettore per schede di circuiti stampati ad...

{kind=link}