Sincronizzare il codice Python in maniera intelligente
-

- Tweet
- Pin It
- Condividi per email
-
In un precedente blog abbiamo sfruttato il tool Tracealyzer di Percepio per ottenere informazioni dettagliate relative a due diverse implementazioni del medesimo algoritmo. In particolare abbiamo stabilito che l’uso di una funzione iterativa per implementare un algoritmo di generazione della sequenza di Fibonacci permetteva di ottenere migliori prestazioni rispetto all’utilizzo di una funzione ricorsiva. Non è stato necessario produrre un numero elevato di elementi della sequenza misurandone i tempo di generazione per identificare la differenza di prestazioni: al contrario, l’utilizzo di Tracealyzer ci ha permesso di ottenere informazioni dettagliate sulle prestazioni delle due implementazioni generando solamente dieci elementi della sequenza.
Poiché il generatore della sequenza di Fibonacci è stata implementato in Python, è utile approfondire ulteriormente questo aspetto. Alcune delle domande più frequenti su StackOverflow riguardano l’implementazione più efficiente e “adatta a Python” di un particolare algoritmo. In questo articolo esamineremo un’operazione molto diffusa: l’inversione di una lista.
Questa domanda su StackOverflow ha dato vita ad alcune discussioni relative alle prestazioni di un’implementazione rispetto a un’altra quando si esegue l’inversione di una lista. Per meglio comprenderne le differenze, possiamo utilizzare entrambe le tecniche in una semplice applicazione come mostrato nel listato seguente: abbiamo anche incluso il codice sorgente necessario per acquisire i marcatori (marker) richiesti da Tracealyzer per valutare le prestazioni di ciascuna implementazione:
import lttngust
import logging
def example():
list_basis = list(range(10))
logging.basicConfig()
logger = logging.getLogger(‘my-logger’)
logger.info(‘Start’)
reverse_list = reversed(list_basis)
logger.info(‘Stop’)
logger.info(‘Start’)
reverse_list = list_basis[::-1]
logger.info(‘Stop’)
if __name__ == ‘__main__’:
example()
Abbiamo creato una lista di 10 elementi e utilizzato la funzione “reversed” integrata unitamente a una tecnica denominata “slicing” in Python per invertire la lista. La tecnica dello slicing consiste nel prelevare determinati elementi da una lista restituendoli a una nuova lista: nel caso in esame abbiamo effettuato lo slicing di tutta la lista, ma con un attraversamento in ordine inverso (traversing backwards).
Come nel precedente post, possiamo creare una sessione LTTng, eseguire lo script Python, aprire il trace risultante in Tracealyzer e valutare i risultati (Fig. 1):
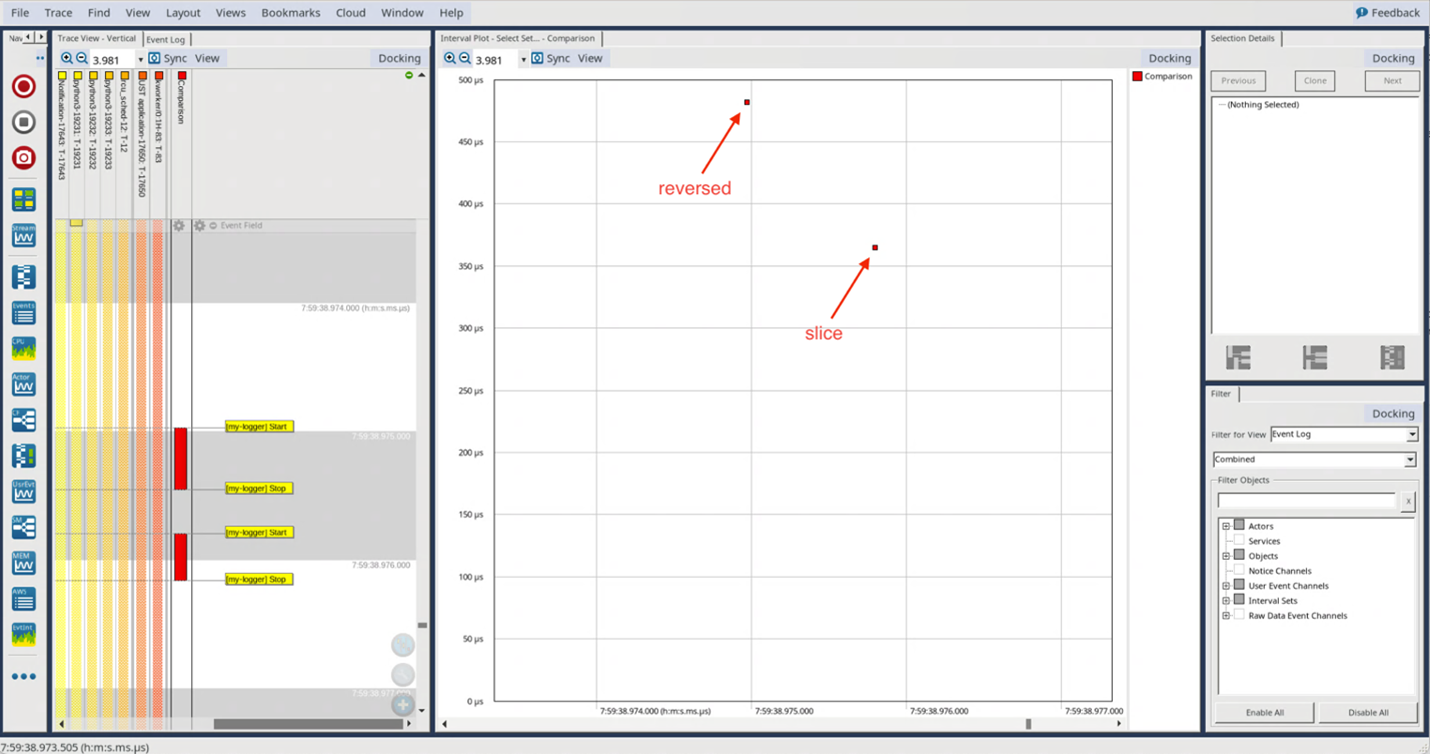
Fig. 1
La figura 1 mostra che l’implementazione mediante la funzione inversa richiede circa 475 microsecondi mentre quella che utilizza lo slicing richiede circa 360 microsecondi.
Vediamo ora cosa succede incrementando il numero di elementi della lista iniziale di un fattore pari a 10, in modo da formare una lista di 100 elementi:
import lttngust
import logging
def example():
list_basis = list(range(100))
logging.basicConfig()
logger = logging.getLogger(‘my-logger’)
logger.info(‘Start’)
reverse_list = reversed(list_basis)
logger.info(‘Stop’)
logger.info(‘Start’)
reverse_list = list_basis[::-1]
logger.info(‘Stop’)
if __name__ == ‘__main__’:
example()
Anche in questo caso eseguiamo nuovamente tutti i passi necessari per creare una sessione LTTng, facciamo girare l’applicazione e apriamo i trace risultanti con Tracealyzer, ottenendo il grafico riportato in figura 2.
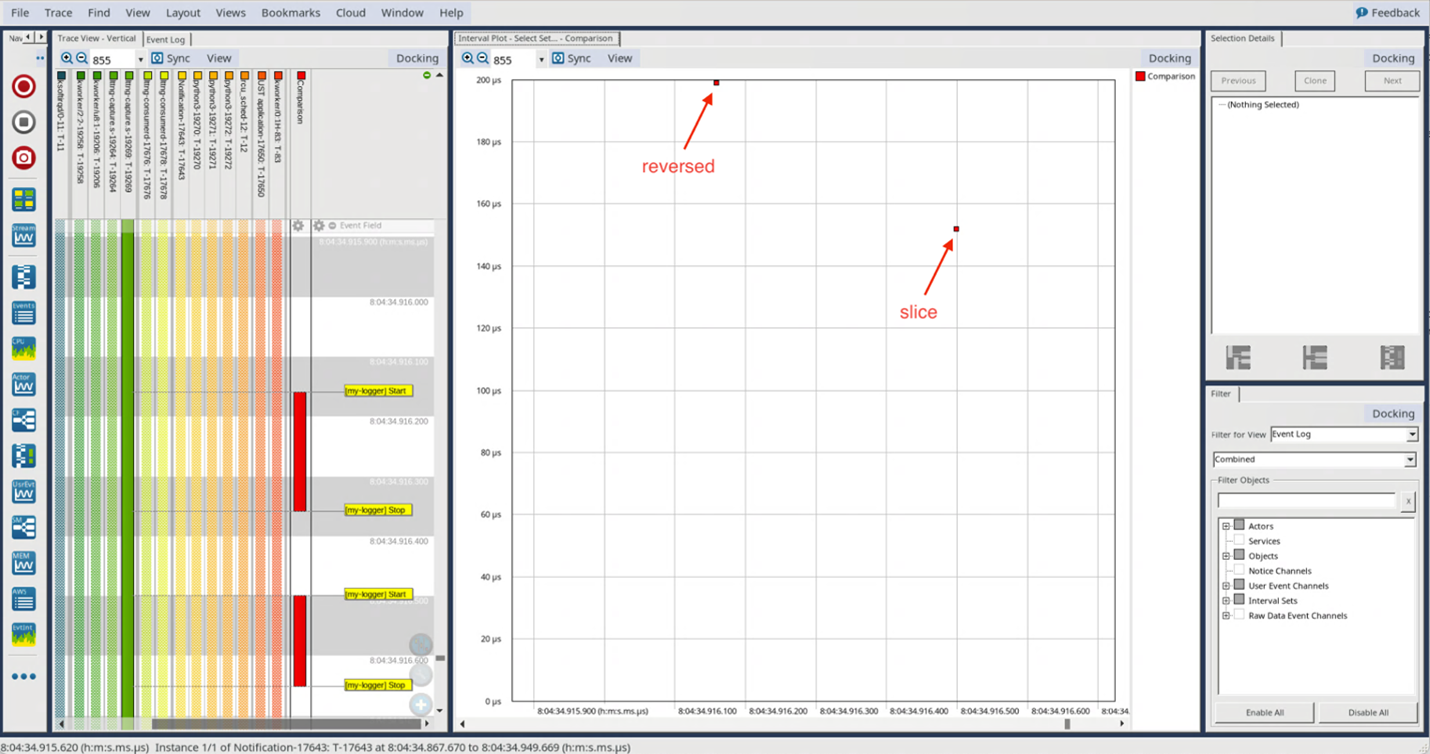
Fig. 2
Sebbene si ottenga un diagramma simile al caso precedente, con lo slicing che assicura migliori prestazioni rispetto alla funzione inversa, possiamo notare che il tempo assoluto per entrambi i meccanismi sia quasi dimezzato rispetto a quello richiesto per una lista con soli 10 elementi. E’ sorprendente, in quanto ci saremmo aspettati che il tempo richiesto con entrambe le tecniche sarebbe stato inferiore nel caso della lista di 10 elementi rispetto a quello con 100 elementi. A questo punto acquisiamo un numero maggiore di dati, aggiornando dapprima lo script Python in modo da raccoglierne di più in maniera automatica:
import lttngust
import logging
import sys
def example(list_size):
list_basis = list(range(list_size))
logging.basicConfig()
logger = logging.getLogger(“my-logger”)
logger.info(“Start”)
reverse_list = reversed(list_basis)
logger.info(“Stop”)
logger.info(“Start”)
reverse_list = list_basis[::-1]
logger.info(“Stop”)
if __name__ == ‘__main__’:
example(int(sys.argv[-1]))
Nell’esempio sopra riportato ci siamo semplicemente concessi di poter passare il numero di elementi che vogliamo alla lista. Quindi possiamo creare il seguente “bash script” che ci consentirà di eseguire l’applicazione Python, passandole come argomento 10 o 100 in momenti successivi, acquisendo il tempo richiesto per invertire la lista utilizzando entrambi i metodi – funzione inversa e slicing – e archiviando i dati. Lo script eseguirà ciascun un ciclo 10 volte.
#!/bin/bash
set -e
list_compare() {
echo “Running test with a list size of $1 elements”
lttng create
lttng enable-event –kernel sched_switch
lttng enable-event –python my-logger
lttng start
python3 list_compare.py $1
lttng stop
lttng destroy
}
for i in {1..10}
do
list_compare 10
cp -r ~/lttng-traces/auto* “/home/pi/percepio/elements_10_trace_$i”
chown -R pi: “/home/pi/percepio/elements_10_trace_$i”
mv ~/lttng-traces/auto* ~/lttng-traces/archive/
list_compare 100
cp -r ~/lttng-traces/auto* “/home/pi/percepio/elements_100_trace_$i”
chown -R pi: “/home/pi/percepio/elements_100_trace_$i”
mv ~/lttng-traces/auto* ~/lttng-traces/archive/
done
Se apriamo i trace risultanti in Tracealyzer e li rappresentiamo in un grafico, osserveremo i seguenti trend (Fig. 3):
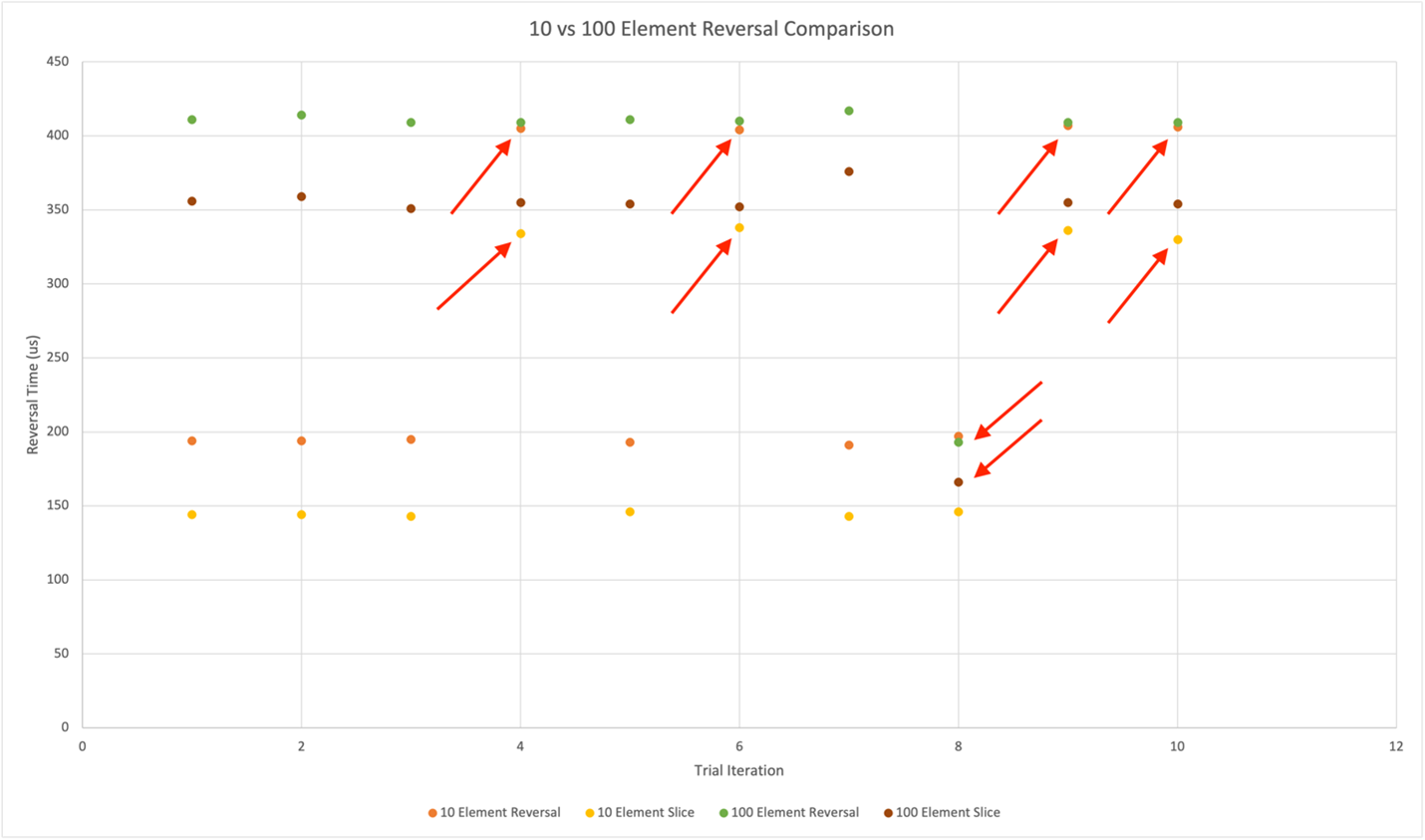
Fig. 3
I grafici con i pallini gialli e arancioni rappresentano i tempi di inversione per la lista di 10 elementi, mentre i grafici con i pallini verdi e rosso scuro rappresentano i tempi di inversione per la lista di 100 elementi. Possiamo osservare alcune istanze in cui i tempi di esecuzione per l’inversione delle liste di 10 elementi sono compatibili con i tempi di esecuzione delle liste di 100 elementi. In modo del tutto analogo, possiamo osservare che in una istanza il tempo di esecuzione dell’inversione di una lista di 100 elementi è diminuito ed in linea con il tempo di esecuzione richiesto per invertire una lista di 10 elementi. Complessivamente, è possibile osservare che il tempo di esecuzione necessario per invertire una lista di 10 elementi è circa la metà di quello richiesto per eseguire la medesima operazione su una lista di 100 elementi.
Abbiamo forse osservato una di queste anomalie nel caso precedente? Analizziamo ora i risultati con una lista di 1000 elementi (Fig. 4):
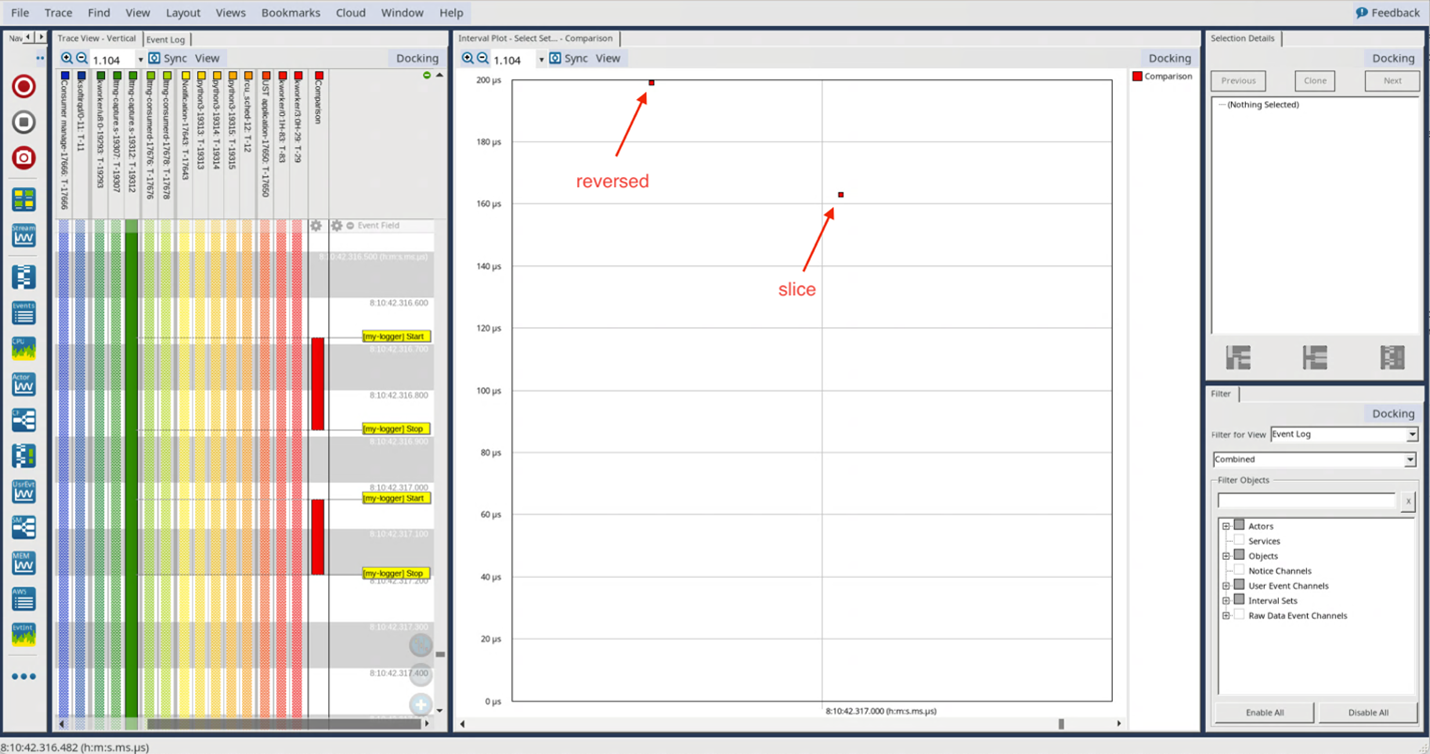
Fig. 4
Anche questa volta osserviamo il medesimo comportamento, che mostra che la tecnica di slicing richiede tempi inferiori rispetto alla funzione inversa. In ogni caso, anche se abbiamo ancora aumentato il numero degli elementi della lista di un fattore pari a 10 (fino a 1.000 elementi), il tempo richiesto per ciascuna implementazione è all’incirca il medesimo di quello necessario per la lista di 100 elementi, e ancora una volta la metà rispetto al tempo necessario per la lista di soli 10 elementi.
A questo punto incrementiamo la lista a 100k elementi e osserviamo i risultati (Fig. 5):
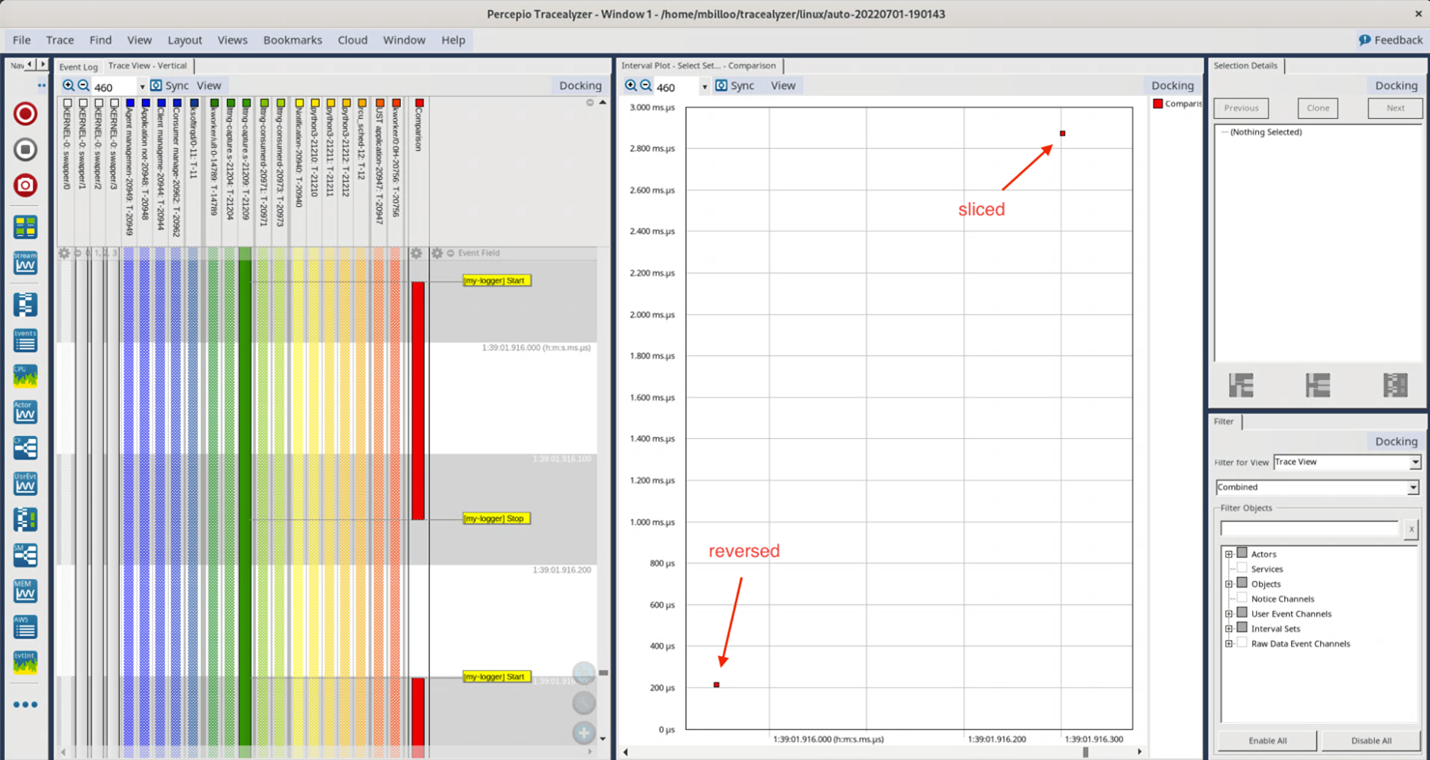
Fig. 5
A differenza di quanto precedentemente rilevato, ovvero che lo slicing richiede all’incirca metà del tempo rispetto alla funzione inversa, in questo caso otteniamo il risultato opposto. Con una lista di 100k elementi, lo slicing richiede un tempo superiore di un fattore pari a circa 15!
In definitiva, questo semplice esercizio ci ha permesso di ottenere preziose informazioni. In primo luogo, sembra che la tecnica dello slicing richieda tempi inferiori rispetto alla funzione inversa nel caso di liste composte da un un numero abbastanza ridotto di elementi (fino a 1.000). Aumentando le dimensioni della lista a 100.000 elementi, lo slicing richiede un tempo di circa 15 volte superiore rispetto alla funzione inversa. In secondo luogo, quando eseguiamo più iterazioni di liste di dimensioni più ridotte, osserviamo istanze in cui il tempo richiesto per invertire una lista di 100 elementi è all’incirca lo stesso di quello necessario per invertire una lista di 10 elementi. La tendenza generale, comunque, è che il tempo richiesto per invertire una lista di 10 elementi è minore rispetto a quello necessario per eseguire la medesima operazione su una lista di 100 elementi. Un risultato questo ampiamente previsto. Possiamo analizzare in maggior dettaglio il trace acquisito da Tracealyzer per comprendere le cause delle anomalie riscontrate.
Il punto chiave qui è che Tracealyzer di Percepio ci ha permesso di eseguire questa analisi dettagliata senza ricorrere a una onerosa infrastruttura di instrumentazione: siamo stati in grado di distinguere numeri relativi alle prestazioni che sono dell’ordine delle centinaia di microsecondi.
Poiché Python è un linguaggio ampiamente utilizzato per le applicazioni di apprendimento automatico (ML Machine Learning) è di fondamentale importanza poter disporre di un tool che ci consenta in tempi brevi di confrontare le prestazioni di un algoritmo rispetto ad un altro. Possiamo sviluppare funzioni di ridotte dimensioni che isolano l’algoritmo che stiamo cercando di valutare e usare Tracealyzer per ottenere le necessarie informazioni circa le prestazioni dell’algoritmo con set di dati di dimensioni variabili. Tracealyzer è anche in grado di scoprire rapidamente comportamenti anomali che potrebbero richiedere ulteriori analisi.

Mohammed Billoo, fondatore di MAB Labs, LLC (www.mab-labs.com), può vantare un’esperienza di oltre 12 anni nella definizione di architetture, progettazione, implementazione e collaudo di software embedded, con una particolare enfasi su Linux embedded. La sua attività spazia dal bring-up di schede custom allo sviluppo di driver e di codice applicativo. Mohammed è un attivo contributore per il kernel Linux e partecipa a numerose attività nell’ambito dell’open source.
E’ professore aggiunto di Ingegneria Elettrica presso la “Cooper Union for the Advancement of Science and Art” dove insegna ai corsi di Logica digitale, Progettazione e Architetture di Computer.
Mohammed ha conseguito la laurea e il successivo master in Ingegneria Elettrica presso la stessa istituzione
Contenuti correlati
-
 Un pacchetto di driver Open-Source nativo Python per la strumentazione da Tektronix
Un pacchetto di driver Open-Source nativo Python per la strumentazione da TektronixTektronix ha introdotto un pacchetto di driver per strumenti Python Open-Source. Questo pacchetto, chiamato tm_devices, è disponibile gratuitamente e offre un’esperienza utente nativa in Python per l’automazione degli strumenti. tm_devices è progettato per funzionare su un’ampia gamma...
-
 Utilizzo dei tool di trace in ambiente Linux
Utilizzo dei tool di trace in ambiente LinuxMohammed Billoo, fondatore di MAB Labs, una realtà specializzata nel fornire servizi di ingegnerizzazione di software embedded, utilizza Linux embedded su una molteplicità di piattaforme hardware. Billoo ha valutato in che modo il nuovo supporto di Percepio...
-
 TRACE32: il nuovo modulo Python
TRACE32: il nuovo modulo PythonLauterbach ha rilasciato la versione 1.0 del suo nuovo modulo Python che permette agli sviluppatori embedded di scrivere test Python nativi utilizzando le “Remote API” di TRACE32. In questo modo gli sviluppatori possono creare applicazioni che controllano...
-
 Aumentare la produzione di cibo richiede creatività (2a Parte)
Aumentare la produzione di cibo richiede creatività (2a Parte)A distanza di un mese dal momento in cui sono stati resi noti i dettagli del “Agritech Challenge” proposto dal laboratorio CLICK del Politecnico di Torino, tutti e tre i team in gara sono ora duramente impegnati...
-
 Agilent: rilasciata la nuova versione di Command Expert
Agilent: rilasciata la nuova versione di Command ExpertAgilent Technologies ha rilasciato la nuova versione di Command Expert, software che permette di velocizzare e semplificare il controllo della strumentazione all’interno di numerosi ambienti di sviluppo delle applicazioni La release include ora il supporto per Phyton,...
Scopri le novità scelte per te
-
Un pacchetto di driver Open-Source nativo Python per la strumentazione da Tektronix
Tektronix ha introdotto un pacchetto di driver per strumenti Python Open-Source. Questo pacchetto, chiamato tm_devices, è disponibile...
-
Utilizzo dei tool di trace in ambiente Linux
Mohammed Billoo, fondatore di MAB Labs, una realtà specializzata nel fornire servizi di ingegnerizzazione di software embedded,...

News/Analysis Tutti ▶
-
 Tecnologia AMD per il supercomputer Hunter
Tecnologia AMD per il supercomputer HunterHunter è il supercomputer recentemente inaugurato dall’HLRS (High Performance Computing Centre) di Stoccarda progettato...
-
 Nuovo riflettometro ad alta risoluzione da Yokogawa Test & Measurement
Nuovo riflettometro ad alta risoluzione da Yokogawa Test & MeasurementYokogawa Test & Measurement ha realizzato un nuovo riflettometro ad alta risoluzione. Siglato AQ7420....
-
 Infineon espande la produzione in Asia
Infineon espande la produzione in AsiaInfineon Technologies ha iniziato i lavori per la realizzazione di un nuovo sito di...
Products Tutti ▶
-
 Il primo modulo Wi-Fi 7 di u-blox per l’automotive
Il primo modulo Wi-Fi 7 di u-blox per l’automotiveu-blox ha annunciato la disponibilità dei primi campioni di RUBY-W2, il suo modulo Wi-Fi...
-
Nuovo riflettometro ad alta risoluzione da Yokogawa Test & Measurement
Yokogawa Test & Measurement ha realizzato un nuovo riflettometro ad alta risoluzione. Siglato AQ7420....
-
 Infineon presenta la famiglia di IC MOTIX
Infineon presenta la famiglia di IC MOTIXMOTIX Bridge BTM90xx è una nuova famiglia di IC di Infineon progettati specificamente per...

{kind=link}