















 50 / 102
50 / 102

DIGITAL
BIG DATA
50
- ELETTRONICA OGGI 448 - SETTEMBRE 2015
“Big Data”, un approccio
di tipo innovativo
S
i sente parlare sempre più spesso di “big data” in ambi-
ti ormai molto differenti fra di loro, ma che significa?
Innanzitutto l’articolo cerceherà di chiarire il significato di
questa espressione e poi analizzerà quali sono gli ambiti appli-
cativi e l’importanza che assume – da qualche anno a questa
parte – tale disciplina scientifica.
Un primo chiarimento potrebbe arrivare sapendo che, per gli
addetti ai lavori, si parla sostanzialmente di “data science”, ovve-
ro di scienza del trattamento dei dati, e nello specifico di grandi
quantità di dati, tanto grandi che non possono essere trattati con
gli strumenti (software) tradizionali, vale a dire data-base assimi-
lati o strumenti statistici come oggi conosciuti.
Ambiti differenti, obiettivi comuni
Di per sé, il termine “data science” potrebbe comunemente esse-
re interpretato come un tipico ambito applicativo degli strumenti
di analisi statistica; e in parte lo è. Tale concetto implica altresì
che si debba partire da un’attenta capacità di analisi e di orga-
nizzazione dei dati attraverso uno studio sistematico; e anche
questo è vero. Inoltre, il sistema di analisi utilizzato deve permet-
tere di ottenere per deduzione una sorta di “tendenza” insita nelle
specificità dei dati in esame, tale da poter effettuare eventual-
mente delle previsioni sul comportamento del sistema in esame,
con tanto di stima del grado di “confidenza” dei dati ottenuti.
Tutto ciò è fondamentalmente vero e senz’altro doveroso anche
nelle caratteristiche e negli obiettivi dell’odierna “data science”.
Qual è allora la differenza dalle tecniche statistiche attuali e per-
ché la necessità di un nuovo termine? Vi sono in effetti delle dif-
ferenzema soprattutto delle novità nella quantità e nella struttura
dei dati da analizzare.
Il primo dato di fatto
è la necessità di analizzare volumi di dati
a volte giganteschi
, scaturiti dalla complessità di molti sistemi
odierni, che vanno ad esempio dalle telecomunicazioni alla diffu-
sione dei contagi, dai dati presenti sul web agli spostamenti delle
persone, dai dati prodotti dagli esperimenti scientifici negli acce-
leratori di particelle alla simulazione delle turbolenze nei fluidi,
dall’analisi di milioni di testi simultaneamente fino alla ricerca di
talune parole-chiave nelle comunicazioni vocali di una regione. I
settori vanno infatti dalla sociologia alla biomedica, dalla lingui-
stica alla macroeconomia, dall’informatica alla ricerca in senso
lato.
Ecco il motivo per cui gli strumenti di data-base e di statistica
tradizionali non sono in grado di analizzare volumi di dati così in-
genti. I software per l’analisi dei dati di tipo classico, inoltre, non
sono adatti alla comprensione del significato dei dati analizzati,
poiché sono ottimizzati essenzialmente per un rapido accesso
alle informazioni e una loro schematizzazione di tipo riepiloga-
tivo, senza quindi la capacità di un’adeguata analisi di tipo pre-
dittivo.
A seconda degli ambiti di analisi, inoltre, i dati di partenza posso-
no essere ad esempio di tipo testo, suoni, immagini oppure an-
che video, in un insieme tipicamente del tutto incoerente di dati,
assolutamente non strutturato, e solo raramente già organizzato.
Anche da questo punto di vista è stato necessario sviluppare
degli opportuni strumenti di analisi di tipo innovativo in grado
di consentire una sufficiente organizzazione della mole di dati,
in modo da creare degli insiemi di tipo coerente. In taluni ambiti
Paolo De Vittor
Le ingenti moli di dati che scaturiscono da
un’ampia gamma di processi odierni richiedono
strumenti di analisi sostanzialmente differenti da
quelli di tipo tradizionale e addirittura il ricorso a
dispositivi di calcolo progettati ad hoc
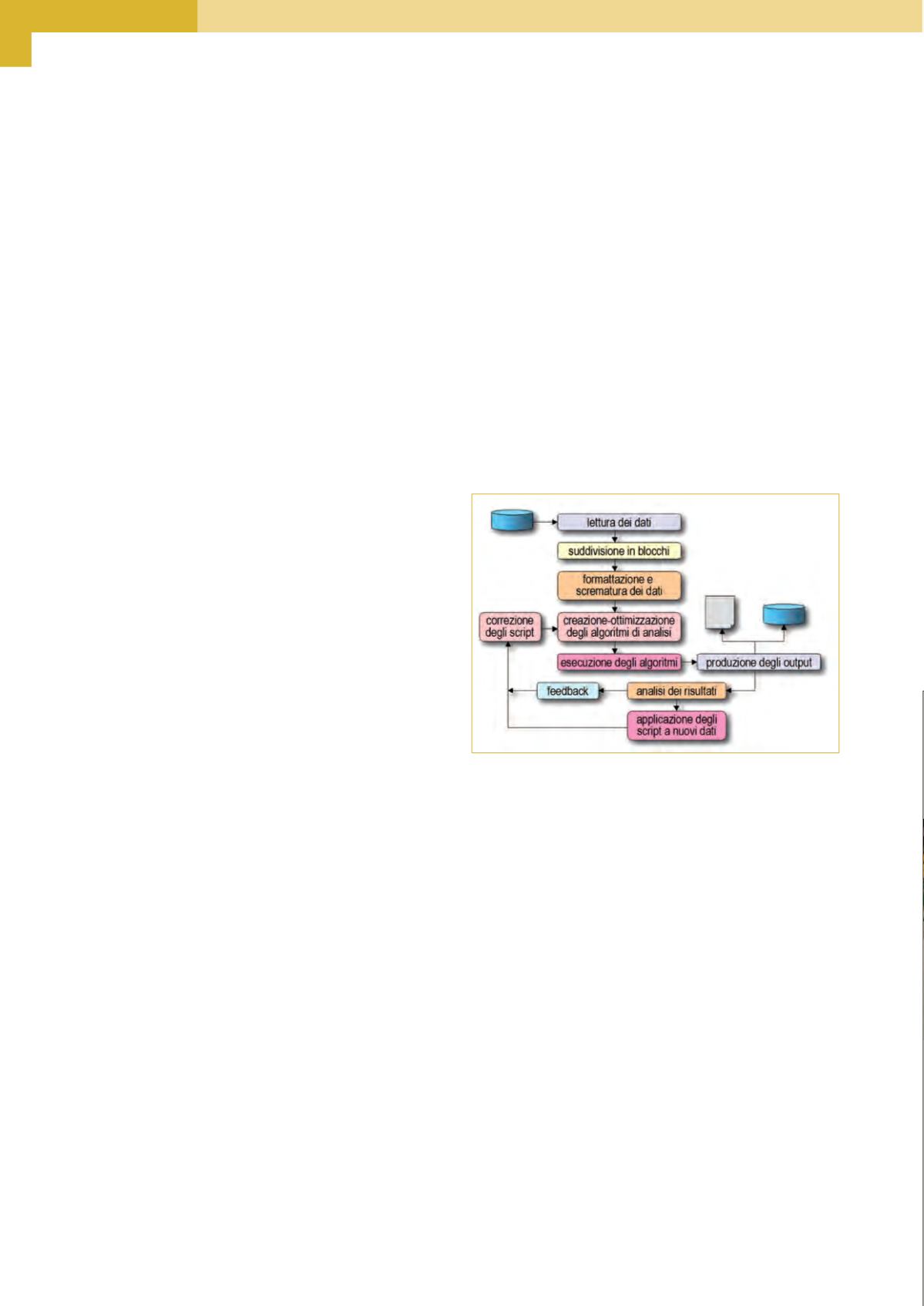
Fig. 1 – Una tipica organizzazione del flusso di lavoro durante l’analisi
dei “big data”