





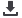










 48 / 102
48 / 102


DIGITAL
FPGA & PROCESSOR
48
- ELETTRONICA OGGI 450 - NOVEMBRE/DICEMBRE 2015
I progettisti non devono comunque limitarsi ai core di pro-
cessore “soft” proposti da un fornitore. Basata sull’architettura
Sparc originariamente sviluppato da Sun Microsystems (ora
parte di
Oracle), la famiglia di core Leon e OpenRISC 1200 è
composta da blocchi IP open-source disponibili da fonti indi-
pendenti. I core occupano in genere più spazio sul die rispet-
to ai softcore LatticeMico32, Microblaze o Nios – tipicamente
da 1,5 a 2 volte maggiore in termini di elementi logici utiliz-
zati in un’architettura basata su tabelle di ricerca a quattro
ingressi convenzionali – ma si propongono come alternative
flessibili ai core fornito dai produttori.
La natura intrinsecamente programmabile degli FPGA con-
sente al progettista di costruire processori custom. Le archi-
tetture dei SoC delle famiglie Cyclone e Zynq sono state svi-
luppate espressamente per questo obbiettivo – i dispositivi di
entrambe le famiglie dispongono di ampi bus I/O per il trasfe-
rimento di una grande quantità di dati tra il processore e le
sezioni di logica programmabile.
Elaborazione a elevata velocità
Nel corso degli anni, i fornitori di FPGA hanno aggiunto il sup-
porto per il calcolo ad alta velocità, specialmente nel caso
di applicazioni di elaborazione del segnale. I moltiplicatori
possono occupare un’area molto ampia in un’architettura
standard basata su elementi LUT (Look-Up Table). Il modo
più efficace per implementare la moltiplicazione nelle celle
programmabile prevede l’uso dell’aritmetica seriale. I molti-
plicatori sono lenti perché lavorano aggiungendo e trasferen-
do un bit alla volta. I moltiplicatori seriali rappresentano una
valida soluzione se utilizzati in array paralleli massivi, perché
possono supportare elevate velocità di trasmissione di dati
aggregati. La semplicità e la natura compatta dei moltiplicato-
ri seriali consente di integrarne un gran numero in un unico
FPGA. Se la latenza non è un parametro critico, l’adozione di
questo approccio rappresenta una valida scelta.
Per accelerare l’elaborazione, i produttori di FPGA hanno
aggiunto la logica carry-chain (a catena di riporto) per con-
sentire ai progettisti di implementare addizionatori carry-lo-
okahead e carry-save più veloci nella logica programmabile.
Molte architetture FPGA, compresi quelle con cui sono rea-
lizzati dispositivi ottimizzati in termini di costi come la serie
Cyclone di Altera e Spartan-6 di Xilinx, ora includono blocchi
moltiplicatore hardware per l’utilizzo in applicazioni DSP ad
alta velocità. Questi blocchi possono essere piuttosto com-
patti al fine di ridurre l’occupazione di area sul die, anche se
possono essere facilmente connessi per dar vita a moltiplica-
tori a 32 e 64 bit più sofisticati utilizzando celle logiche pro-
grammabili per supportare funzionalità più sofisticate come
l’aritmetica in virgola mobile. Alcune architetture prevedono
una varietà di core DSP per soddisfare esigenze specifiche
delle applicazioni finali.
wQuesti core contengono molteplici unità a 9 bit per l’elabo-
razione di immagini e video e core di maggiori dimensioni
utilizzati per segnali audio e comunicazioni. Nella figura 3 è
riportato un esempio di blocco DSP integrato nella famiglia di
dispositivi LatticeEcp.
Grazie alla natura programmabile della struttura FPGA, è
possibile creare coprocessori che si adattano alle esigenze
del sistema. La riconfigurazione parziale permette di inte-
grare diversi blocchi coprocessore nella struttura, che una
volta terminata l’elaborazione richiesta vengono sostituiti per
eseguire l’elaborazione di un altro algoritmo. Ad esempio, in
un algoritmo di elaborazione audio, la struttura FPGA può
eseguire l’elaborazione spettrale mediante la trasformata di
Fourier veloce (FFT) seguita dal filtraggio, eseguito mediante
un filtro FIR (Finite Impulse Response) che è caricato nella
medesima sezione una volta completata l’analisi spettrale.
Programmabilità
La programmabilità della struttura FPGA contribuisce anche
a semplificare il flusso di dati attraverso un elemento copro-
cessore. Nel caso di una trasformata FFT, le implementazioni
dell’algoritmo in un processore di tipo general purpose sono
spesso relativamente lente, perché la modalità di accesso ai
dati di tipo “butterfly” richiesto da questo algoritmo implica
ripetute operazioni di caricamento e scrittura di valori tem-
poranei nella cache o nella memoria principale: a causa della
latenza di tali accessi si può verificare il fatto che le unità
aritmetico logiche (ALU) si trovino “a corto” di dati. Grazie alla
Fig. 3 – Schema di un blocco DSP integrato negli Fpga della famiglia
LatticeECP