

















 48 / 86
48 / 86

DIGITAL
ULTRA LOW POWER DESIGN
48
- ELETTRONICA OGGI 469 - APRILE 2018
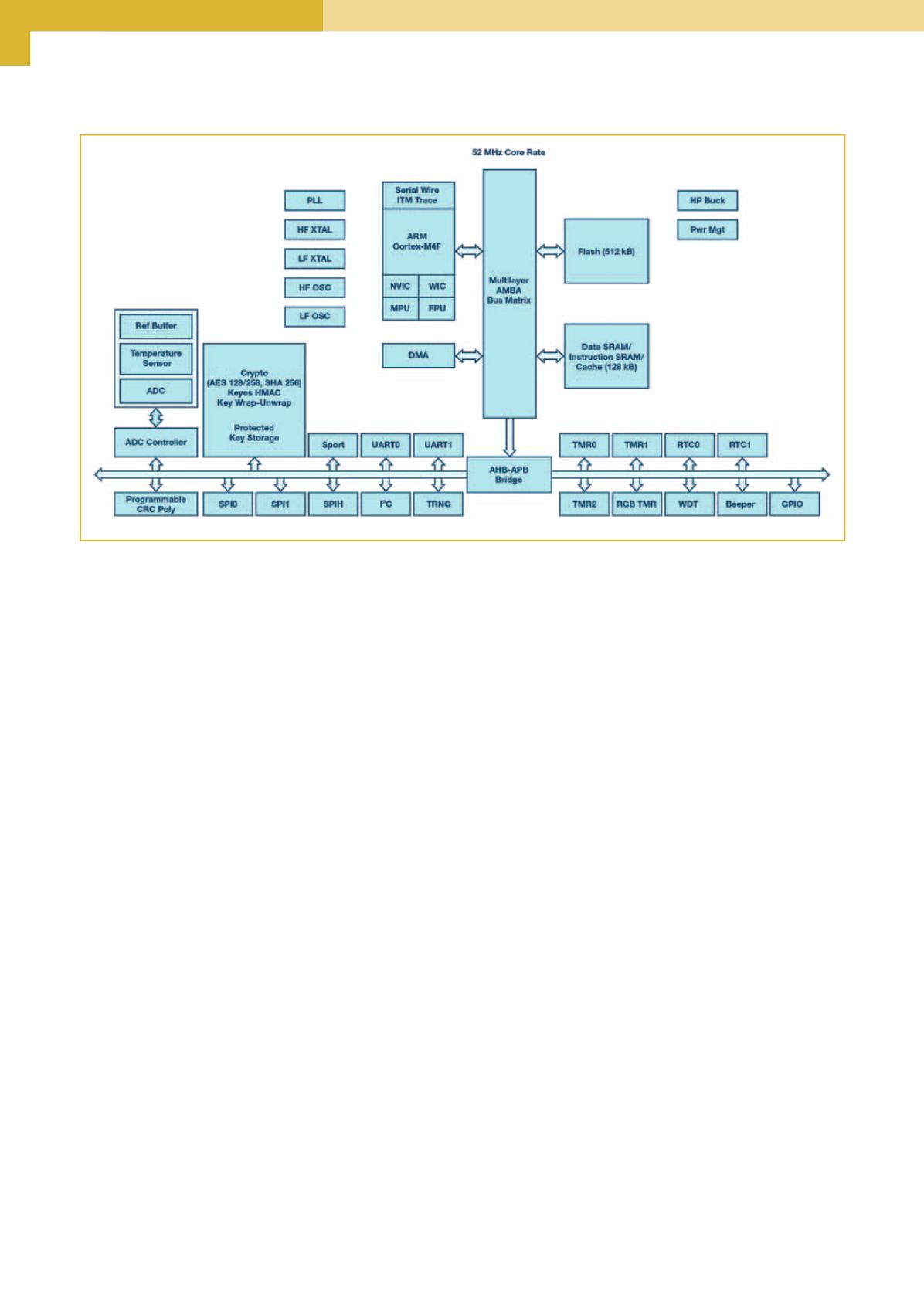
Perché ADuCM4050 consuma 10µA/MHz in più rispetto
ad ADuCM3029? La ragione di questo aumento è do-
vuta al fatto che il primo funziona ad una frequenza
doppia rispetto secondo, richiedendo un buffer supple-
mentare per rientrare nei limiti di tempo imposti dalla
frequenza di clock più elevata. Rispetto ad ADuCM3029,
ADuCM4050 prevede caratteristiche aggiuntive:
•
Quantità di memoria doppia (sia di SRAM che di
Flash): 128 kB e 512 kB rispetto a 64 kB e 256 kB
sull’ADuCM3029. In base alle applicazioni, potrebbe-
ro essere necessarie delle espansioni di memoria.
•
Frequenza di clock doppia: 52 MHz contro 26 MHz
sull’ADuCM3029, per cui l’ADuCM4050 ha prestazio-
ni migliori.
•
Timer RGB aggiunti.
•
Aggiunte di nuove caratteristiche di sicurezza: me-
morizzazione protetta della chiave con cifratura/de-
cifratura e HMAC a decifratura di chiave.
•
Aggiunte di tre uscite supplementari SensorStrobe.
•
Aggiunta della completa permanenza dei dati su
SRAM: ADuCM4050 mantiene fino a 124 kB, contro i
32 kB dell’ADuCM3029.
A seconda delle specifiche applicative (ottimizzazione
dei consumi, memoria supplementare, prestazioni mo-
dalità attiva, mantenimento dei dati…), è possibile de-
cidere se utilizzare ADuCM4050 oppure ADuCM302x.
Per quanto riguarda la modalità deep-sleep, pur dispo-
nendo di una memoria doppia rispetto ad ADuCM3029
(16 kB contro gli 8 kB di quest’ultimo), nell’eseguire
l’ULPMark-CoreProfile l’ADuCM4050 raggiunge cor-
renti di ibernazione più basse. La ragione di quest’e-
voluzione risiede nelle architetture migliorate del più
recente ADuCM4050.
Il ruolo del compilatore
Come si è detto in precedenza, ULPMark comprende
due stati operativi – uno stato attivo ed uno low power,
dove il dispositivo si trova in sleep mode. Questi stati
vengono combinati in un duty cycle della durata esat-
ta di 1 secondo. Nello stato attivo, ciascun dispositivo
esegue le medesime funzioni. Ma come abbiamo già
notato, l’efficienza del lavoro eseguito viene influenza-
ta dall’architettura. Inoltre, viene anche condizionata
dal compilatore. I compilatori possono scegliere di
cambiare e ottimizzare gli statement, cambiando così
l’insieme delle istruzioni.
A seconda delle necessità applicative, si può ottimizza-
re per dimensione, per velocità, o per cercare un equi-
librio tra le due ecc. La semplificazione del Loop (Loop
unrolling) è un semplice esempio nel quale il rapporto
dei branch eseguiti dal codice all’interno del loop vie-
ne variato. I compilatori possono ancora giocare un
ruolo importante nell’ottimizzazione della computazio-
ne a parità di lavoro eseguito. Ad esempio, il risultato
ULPMark-CP per l’ADuCM3029 potrebbe passare da
245,5, con un’alta ottimizzazione per la velocità, a 232
per un’ottimizzazione media, o a 209 con un basso li-
vello di ottimizzazione. Un altro esempio dell’importan-
za del compilatore è dimostrato dai risultati ULPMark
per un Texas Instruments MSP430FR5969, che miglio-
rano del 5% utilizzando una versione più recente del
compilatore IAR Embedded Workbench— sebbene
non sia noto quali variazioni siano state apportate in-
ternamente al compilatore stesso per raggiungere que-
sti miglioramenti
(eembc.org/ulpbench/). Allo stesso
modo, senza addentrarsi nella tecnologia proprietaria
del compilatore, non è possibile determinare perché
Fig. 3 – Schema a blocchi dell’ADuCM4050: esso integra un regolatore low-dropout (LDO) da 1,2V e un circuito buck capacitivo opzionale