



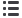












 72 / 102
72 / 102

EDA/SW/T&M
SoC
72
- ELETTRONICA OGGI 448 - settembre 2015
trappola dei minimi locali, garantendo di
conseguenza un’ottimizzazione globale
degli elementi PPA.
Ottimizzazione avanzata timing
e power-driven
Ci sono diverse tecniche per iniziare a
ottimizzare timing e consumi già nelle
fasi preliminari del progetto. Una delle
tecniche consiste nel fare un uso ottimale
degli strati metallici superiori per il rou-
ting. Tali layer offrono infatti parametri di
resistenza migliori e aiutano a rispettare
il timing, riducendo le perdite e i consu-
mi dinamici. Gli strati superiori dei livelli
metallici hanno larghezze e spaziature
predefinite diverse da quelle degli stra-
ti inferiori. Come risultato, i ritardi dei
conduttori negli strati superiori possono
essere inferiori anche di 10 volte rispetto
a quelli degli strati inferiori, assicurando
un grande vantaggio in termini di timing.
Naturalmente, le risorse di routing disponibili sugli strati me-
tallici superiori sono necessariamente limitativa causa della
presenza delle reti di alimentazione. Se non adeguatamente
affrontata, la limitazione di queste risorse può causare poten-
ziali congestioni e problemi di routing nelle fasi successive
del flusso.
Attraverso la sua capacità di ottimizzazione route-aware, l’en-
gine multi-threaded di ottimizzazione timing- e power-driven
del sistema di implementazione Innovus può identificare net
lunghe con criticità temporali, valutare l’impatto sulla conge-
stione degli strati superiori di una nuova infrastruttura per
garantire che ci sia spazio sufficiente, e ri-bufferare tali reti
per migliorare il timing. In questo modo è possibile mantene-
re le assegnazioni dei livelli critici durante l’intero del flusso
di ottimizzazione pre-routing. Queste assegnazioni sono tra-
smesse all’engine di routing globale a elevato parallelismo
del sistema, in modo che anche al routing finale possa essere
assegnato il livello corretto.
Migliore variabilità cross-corner
con sincronizzazione concorrente
Il sistema di implementazione Innovus è dotato di un engine
di nuova generazione per l’ottimizzazione concorrente del
clock che garantisce un multi-threading reale, un maggior
useful-skew e una completa integrazione di flusso. Esso fon-
de le attività di ottimizzazione fisica e di sintesi dell’albero di
clock (CTS), procedendo simultaneamente alla costruzione
della struttura di timing e all’ottimizzazione dei ritardi logici
basandosi direttamente su un modello di clock propagato.
Tutte le decisioni di ottimizzazione sono basate su veri clock
propagati, tenendo conto di temporizzazioni di gate, percorsi
inter-clock e riduzione delle variazioni on-chip (OCV).
Il sistema di implementazione Innovus prevede la nuova fun-
zionalità FlexH, che fornisce una struttura topologicamente
più vicina possibile a un H-tree, adottando dei compromessi
tra i diversi vincoli hard e soft. FlexH offre una democratiz-
zazione dell’approccio H-tree nell’ambiente di progettazione
SoC reale.
TAT ridotto fino a 10 volte
Si darà ora uno sguardo più da vicino a come il sistema di
implementazione Innovus sia in grado di migliorare il TAT di
un progetto digitale. Il primo e più importante contributo vie-
ne dalla sua architettura full-flow a elevato parallellismo che
permette di eseguire attività multi-thread simultaneamen-
te su più CPU. L’architettura è stata progettata in modo tale
che il sistema possa garantire TAT all’avanguardia pur uti-
lizzando delle risorse hardware standard, che normalmente
prevede da 8 a 16 CPU per macchina. Inoltre, in presenza di
progetti con una grande mole di istanze il flusso può essere
scalato su più macchine. L’architettura tiene anche conto dei
passi e degli effetti a monte e a valle del flusso di progettazio-
ne, fornendo un’accelerazione del runtime e minimizzando
le iterazioni di progettazione tra gli engine di placement, otti-
mizzazione, clock e routing.
L’avanzato engine di ottimizzazione timing e power-driven
Fig. 2 – Benchmark di progetti ad alte prestazioni su processore embedded