

















 50 / 102
50 / 102

DIGITAL
ARTIFICIAL INTELLIGENCE
50
- ELETTRONICA OGGI 464 - SETTEMBRE 2017
ziali candidati per assolvere questo compito. I microprocessori
tradizionali, invece, a causa dei “colli di bottiglia” rappresentati
dalla cache – problema questo tipico di qualsiasi architettura ba-
sata sul modello di Von Neumann – sono in grado di far girare
l’algoritmo ma trasferiscono i compiti (task) di astrazione dei la-
yer agli acceleratori hardware. Se da un lato sia GPU che FPGA
offrono notevoli capacità di elaborazione parallela, le prime sono
caratterizzate da un’architettura fissa mentre le seconde, grazie
a un’architettura flessibile e riconfigurabile in modo dinamico,
risultano più idonee per l’accelerazione della CNN. Grazie a un
approccio “a grana fine”, che prevede l’implementazione in har-
dware degli algoritmi della rete CNN, l’architettura degli FPGA
permette minimizzare il tempo di latenza e garantire un maggior
determinismo rispetto a un approccio basato su GPU che utilizza
algoritmi di tipo software. Un altro vantaggio offerto dagli FPGA
è la loro capacità di integrare in hardware, all’interno della strut-
tura del dispositivo, blocchi funzionali come i DSP. Un approccio
di questo tipo contribuisce “rafforzare” ulteriormente la natura
deterministica della rete. In termini di utilizzo di risorse, gli FPGA
risultano molto efficienti: ogni layer della rete CNN può essere
integrato nella struttura stessa dell’FPGA con le risorse di me-
moria nelle immediate vicinanze.
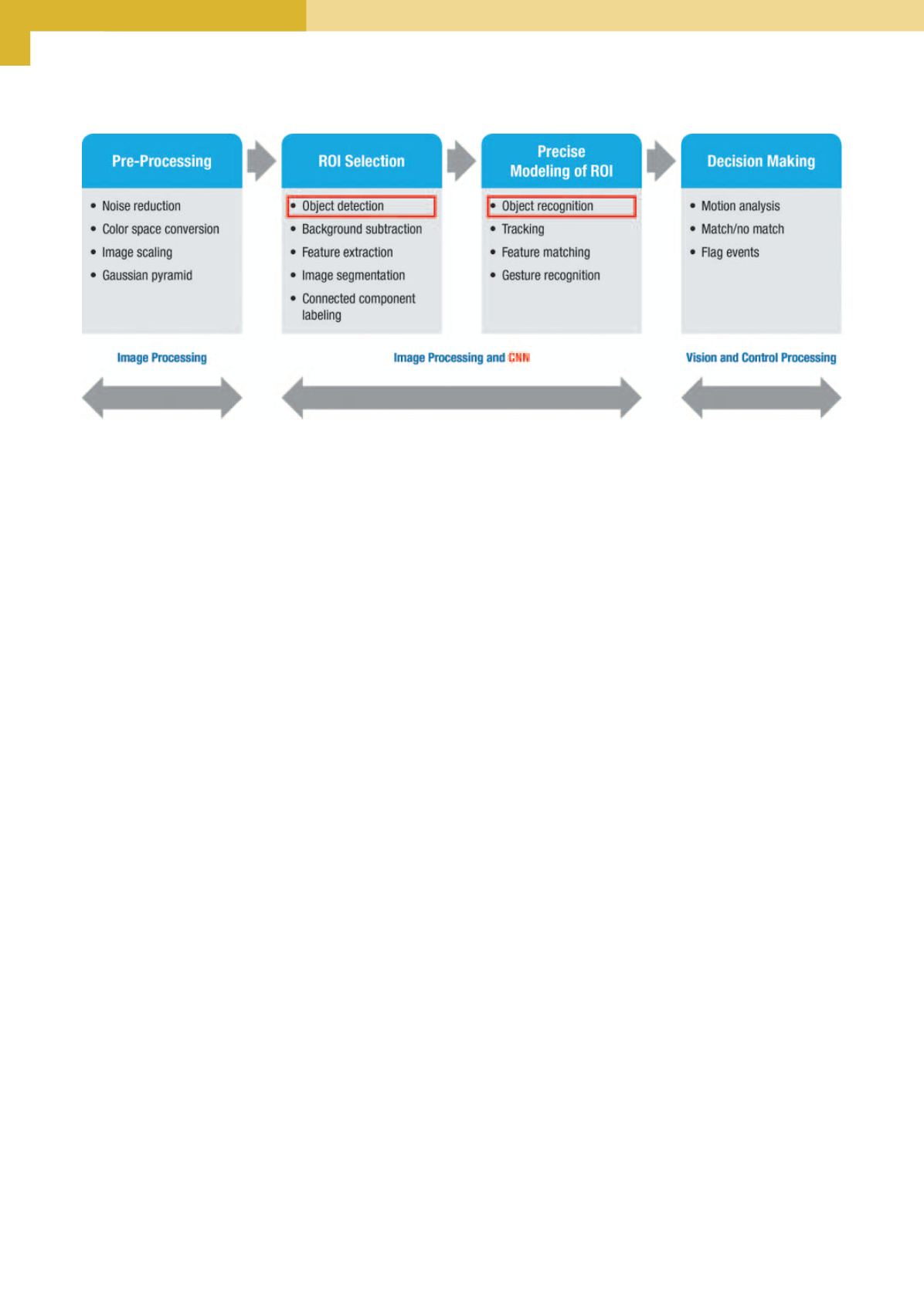
La figura 2 illustra i componenti chiave di una CNN progettata
per un’applicazione industriale di elaborazione delle immagini: i
due blocchi posti al centro rappresentano il nucleo centrale della
rete. Lo sviluppo di applicazioni di accelerazione di una rete CNN
basate su FPGA è completato dalle estensioni del linguaggio C
OpenCL
2a
per la programmazione parallela. Un esempio di FPGA
idonee per l’impiego nelle reti neurali convoluzionali è la serie Ar-
ria 10 del Programmable Solutions Group (PSG) di Intel (ex Altera).
Un utile ausilio per tutti gli sviluppatori coinvolti in progetti di ac-
celerazione di CNN basati su FPGA è rappresentato dal proget-
to di riferimento (reference design) per CNN di Intel PSG. Esso
si avvale dei kernel OpenCL per implementare i layer della rete
CNN. I dati vengono trasferiti da un layer al successivo usando
canali e “pipe”, una funzione che consente il passaggio dei dati
tra i kernel OpenCL senza consumare larghezza di banda del-
la memoria esterna. I layer di convoluzione sono implementati
a partire da dati strutturati e non strutturati, con neuroni creati
dal computer che formano la rete di connessioni e interruzioni
(Fig. 1). L’abbinamento di pattern (patternmatching), un concetto
chiave di una rete CNN, è una tecnica ampiamente usata nell’ap-
prendimento automatico.
La seconda fase di una CNN è quella dell’esecuzione. Un layer
di convoluzione estrae dalla sorgente dell’immagine le caratte-
ristiche di basso livello per rilevare elementi come linee o bordi
all’interno di un’immagine. Altri layer, detti layer di pooling, ser-
vono a ridurre le variazioni effettuando una sorta di media (po-
oling, o più precisamente la riduzione a un singolo valore di una
serie di input in ingresso) delle caratteristiche comuni per una
particolare area dell’immagine. Quindi possono entrare in gioco
altri layer di convoluzione e di pooling. Il numero di layer della
CNN è ovviamente correlato alla precisione del riconoscimento
dell’immagine, anche se un numero più elevato implica la dispo-
nibilità di una maggiore potenza di elaborazione. I layer possono
operare in modo parallelo se l’ampiezza di banda di memoria
è disponibile; a questo proposito è bene tenere presente che la
parte più onerosa, in termini di calcolo, è ascrivibile agli strati di
convoluzione.
La sfida per gli sviluppatori consiste nel mettere a disposizione
risorse di elaborazione sufficienti perché una CNN possa iden-
tificare il numero necessario delle diverse classificazioni delle
immagini nel rispetto dei vincoli temporali di un’applicazione. Ad
esempio, un’applicazione di automazione industriale potrebbe
usare la visione artificiale per identificare in quale fase di lavora-
zione inviare un pezzo mentre passa su un nastro trasportatore.
Fermare il processo temporaneamente per permettere a una rete
neurale di identificare il pezzo comporterebbe l’interruzione del
flusso e il conseguente rallentamento della produzione.
Implementazione di una rete CNN
L’accelerazione di alcune fasi delle operazioni di apprendimento
potenziato e di esecuzione di una CNN aumenterebbe significa-
tivamente la velocità di un’attività di natura prettamentematema-
tica. Grazie alla loro elevata larghezza di banda di memoria e alle
notevoli risorse di calcolo disponibili, GPU e FPGA sono i poten-
Fig. 2 – Blocchi base di una rete CNN utilizzata per applicazioni di riconoscimento dell’immagine (Fonte: Cadence
2
)