


















 53 / 86
53 / 86

EMBEDDED
54 • NOVEMBRE • 2014
53
HARDWARE
MULTICORE
fondamentali: bit level, instruction, data, e task. Bit level
estende l’architettura hardware per operare contemporane-
amente su dati più grandi. Ad esempio, su un core a 8-bit,
il calcolo su un oggetto dati a 16 bit richiede due istruzioni.
Istruzione di parallelismo (ILP, instruction) è la tecni-
ca per identificare istruzioni che non dipendono l’una
dall’altra. Poiché i programmi sono in genere sequen-
ziali in struttura, questo non è un compito facile e al-
cune applicazioni, come l’elaborazione del segnale per
voce e video, possono funzionare in modo efficiente.
Parallelismo dei dati (data) consente a più unità di elabo-
rare i dati contemporaneamente. Una di queste tecniche è
implementata in hardware SIMD (Single Instruction/mul-
tipli di dati), e viene realizzata nelle istruzioni di vettore a
128-bit, definite dal set di istruzioni AltiVec e le istruzioni
vettoriali a 64 bit. Task di parallelismo distribuisce diver-
se applicazioni, processi o thread a diverse unità. Questo
può essere fatto manualmente o con l’ausilio del sistema
operativo.
Software design
Il modo più semplice per passare da single-core a multicore
computing è di eseguire ogni core in modo indipendente.
Questo approccio è chiamato multiprocessing asimmetrico
(AMP o ASMP) in contrasto con SMP (SMP).
In un design AMP, ogni core è dedicato a una singola attivi-
tà, come decodifica dati in entrata o manipolazione di essi.
Questo può essere fatto in un core polivalente o in core pro-
gettati su misura che hanno una unità di sicurezza dedicata
per eseguire la crittografia e la decrittografia, come P2020
di Freescale.
Con i sistemi AMP, è importante che l’hardware distribuisca
il lavoro tra i core. Nel caso di traffico Ethernet, per esempio,
questo può essere fatto mediante filtraggio di indirizzi MAC
o IP per core specifici. Tuttavia, con un design SMP, si ri-
chiedono core omogenei che condividono memoria in modo
tale che qualsiasi processo possa essere assegnato a qualsi-
asi core in qualsiasi momento. Supponendo che un’applica-
zione sia divisa in più thread, questo è un approccio molto
conveniente, poiché il sistema operativo svolge la maggior
parte del lavoro. Tuttavia si verficano perdite di prestazio-
ni, perché tutti i core competono per la stessa memoria.
Combinazioni di SMP e AMP producono buoni risultati in
applicazioni come telecomunicazioni 3G/LTE.
Hardware design
Un obiettivo di progettazione hardware è quello di minimiz-
zare il consumo energetico reso possibile dalla migrazione
a sistemi multicore. I dispositivi di solito implementano i
modi che fermano l’esecuzione o spengono il dispositivo
per diversi gradi. Tuttavia queste modalità possono essere
difficili da attivare nel software, e la riattivazione può ri-
chiedere molto tempo, specialmente se i PLL (phase-lock
loop) richiedono risincronizzazione. Per semplificare que-
sta operazione vengono introdotte nuove tecniche che in-
terrompono l’esecuzione su un core specifico, finché non si
verifica un interrupt.
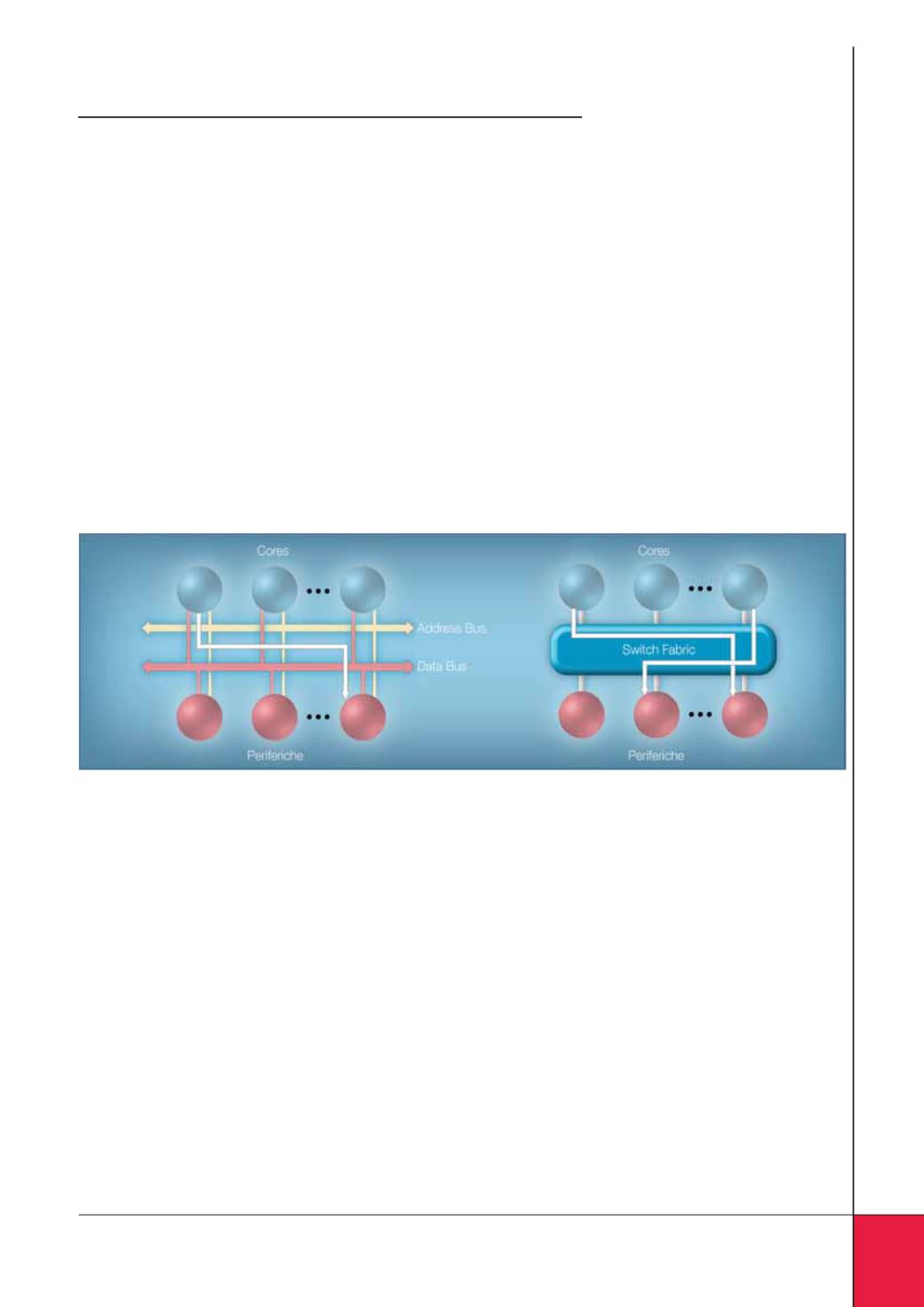
I dispositivi utilizzano in genere un approccio basato su
bus per la comunicazione interna, semplici da progettare
e con un’elevata capacità di trasmissione a bassa latenza.
Tuttavia, dispositivi multicore devono affrontare due gran-
di ostacoli: il numero di unità aumenta, così come la lun-
ghezza fisica della connessione al bus.
La soluzione, mostrata in figura 3 consente accessi multi-
pli simultanei. Con tale approccio, come un core comunica
con l’interfaccia Serial RapidIO, un altro può accedere alla
memoria, un terzo può utilizzare l’interfaccia Ethernet, e
così via.
Fig. 3 – Approccio multi-core per bus