23
- ELETTRONICA OGGI 434 - MARZO 2014
thread 1 acquisisce i dati
restituiti mentre il thread
0 memorizza la somma dei
due valori che ha caricato.
È chiaro che in condizioni
di stato stazionario tutte le
componenti della pipeline
sono attive e ciascuno sta-
dio elabora un thread diffe-
rente.
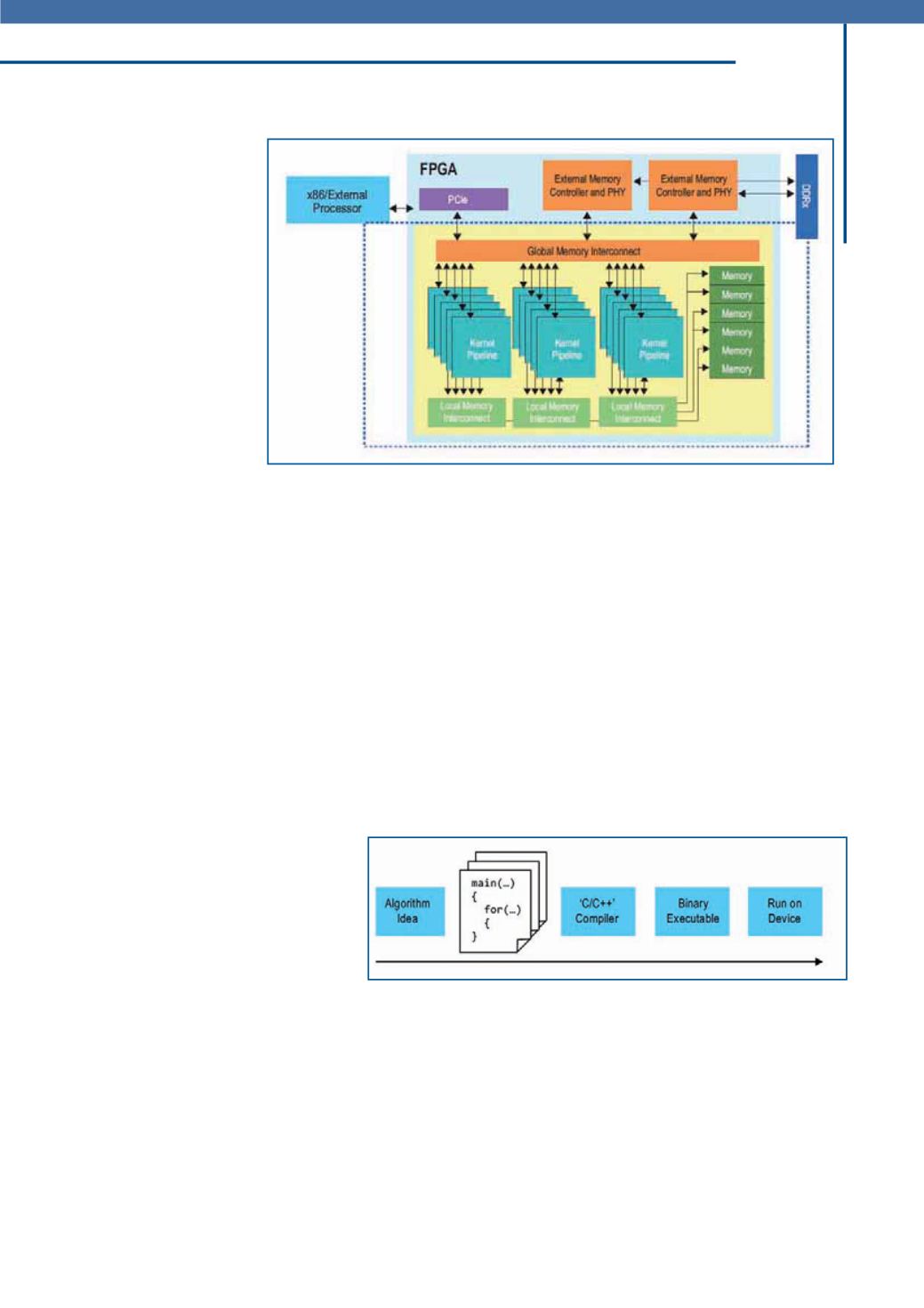
Nella figura 4 è riportata
una rappresentazione ad
alto livello di un sistema
OpenCL completo che pre-
vede più pipeline del ker-
nel e circuiti che collegano
queste pipeline a interfac-
ce dati esterne al chip. Ol-
tre alle pipeline del kernel
il compilatore OpenCL di
Altera genera interfacce per memorie interne ed
esterne. Le unità di caricamento e memorizza-
zione (load & store) per ciascuna pipeline sono
collegate a una memoria esterna attraverso una
struttura di interconnessione globale che si oc-
cupa di arbitrare richieste multiple dirette a un
gruppo di moduli di memoria DIMM DDR. In ma-
niera del tutto analoga gli accessi alla memoria
locale OpenCL sono collegati attraverso una
struttura di interconnessione “ad hoc” alle RAM
M9K on chip. Queste strutture di interconnessio-
ne specializzate sono state progettate in modo da
garantire un’elevata frequenza di funzionamento
e un’organizzazione efficiente delle richieste alla
memoria.
I vantaggi dell’implementazione
di OpenCL su un FPGA
La creazione di progetti basati su FPGA
utilizzando una descrizione OpenCL ga-
rantisce numerosi vantaggi rispetto alle
tradizionali metodologie basate sulla pro-
grammazione HDL. La più significativa vie-
ne schematizzata in figura 5. Il flusso per
lo sviluppo di dispositivi programmabili
via software si articola nelle seguenti fasi:
concezione dell’idea, codifica dell’algorit-
mo in un linguaggio ad alto livello (C ad esem-
pio), utilizzo di un compilatore automatico per
creare il flusso di istruzioni.
Un approccio di questo tipo può essere in con-
trasto con le tradizionali metodologie di progetti
basati su FPGA. In questo caso, la maggior parte
del lavoro è svolta dai progettisti al quale spet-
ta il compito di generare le descrizioni ciclo per
ciclo dell’hardware che sono impiegate per im-
plementare i loro algoritmi. Il flusso tradizionale
prevede la creazione di percorsi dati (datapath)
e di macchine a stati per controllare questi per-
corsi dati, il collegamento a core IP di basso li-
vello mediante tool a livello di sistema (come ad
esempio SOPC Builder e Platform Studio) e la
gestione delle problematiche relative alla “timing
closure” in quanto le interfacce esterne impon-
gono vincoli fissi che devono essere rispettati.
L’obbiettivo del compilatore OpenCL è effettuare
tutte le fasi appena descritte in maniera automa-
tica in modo da consentire ai progettisti di con-
centrare la loro attenzione sulla definizione degli
algoritmi piuttosto che sui dettagli, invero un po’
noiosi, del progetto hardware. Un approccio di
questo tipo consente ai progettisti di migrare
senza problemi su nuovi FPGA caratterizzati da
migliori prestazioni e maggiori capacità perché
il compilatore OpenCL convertirà la medesima
descrizione ad alto livello in pipeline capaci di
sfruttare le potenzialità degli FPGA di nuova ge-
nerazione.
ALTERA
Fig. 5 – Flusso di sviluppo di dispositivi programmabili via software
Fig. 4 – Implementazione di un sistema OpenCl


