

















 62 / 84
62 / 84

EMBEDDED
64 • MAGGIO • 2017
62
SOFTWARE
|
BIG DATA
misurazione dai diversi sistemi di controllo e archi-
viarli e gestirli assieme alle informazioni descrittive
(metadati) conformi all’ODS di ASAM. È possibile
raccogliere i dati di openMDM tramite navigazione
o ricerca, raggrupparli e successivamente fornirli a
diversi strumenti di analisi per perfezionarli.
In tal modo le aziende sono in grado di normalizza-
re i processi di prova dei diversi settori e di gestirli
in modo autonomo rispetto al produttore. La tran-
sizione parte da soluzioni proprietarie e locali per
giungere ad ambienti di lavoro realmente integrati
'
44
4 2 x ' À
con l’approccio aperto e indipendente dal produtto-
re di openMDM è possibile impiegare gli strumenti
(vale a dire sistemi di misurazione, tool di analisi,
programmi di valutazione e così via) dei diversi pro-
duttori ideati appositamente per eseguire al meglio
precisi compiti o fasi di lavoro in un processo di pro-
va di un particolare settore. Malgrado le differenze
tra sistemi, il risultato è una visione coerente e glo-
bale di tutti i dati di prova di un settore.
Uno spazio sufficiente per i risultati di misurazione
La quantità dei dati di prova cresce costantemente
nei vari settori e i dati aumentano continuamente
in base alla tipologia (ad esempio strutturati, non
strutturati, parzialmente strutturati) e ai formati
(
' À _ 5
Y À
y
12 ) À
dati a costi contenuti per eventuali valutazioni fu-
ture, Peak Solution ha proposto di memorizzarli
su hardware “commodity”. Anche in questo caso
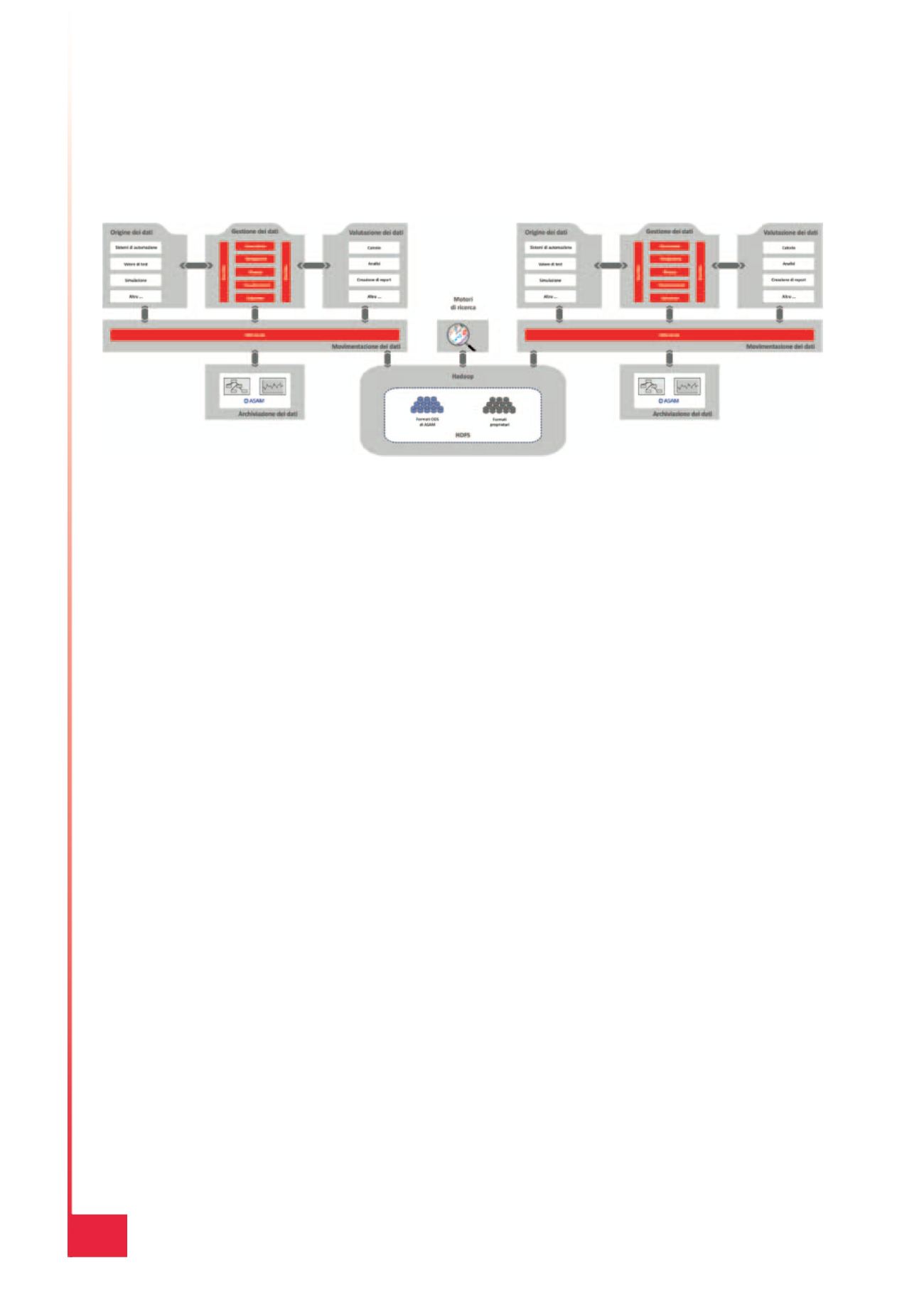
viene fornita una soluzione gratuita: il progetto
open source di Hadoop (Fig. 2), gestito da Apache
Software Foundation, consente l’archiviazione e
l’elaborazione distribuita di grandi quantità di
dati in ambienti orizzontali distribuiti. Un com-
ponente centrale di Hadoop è HDFS (Hadoop Di-
stributed File System). Si tratta di un sistema di
À
7
modo scalabile, sicuro e protetto grandi quantità di
dati in migliaia di server all’interno di un cluster.
La particolarità risiede nel fatto che, a tale scopo,
non sono necessari server particolari o costosi, al
contrario, è possibile utilizzare hardware generici.
Hadoop Distributed File System è circa 20 volte
più conveniente per terabyte rispetto ad esempio
alle Storage Area Network o a database analitici
(come ad esempio Enterprise Data Warehouse).
Non vengono applicati costi per i diritti di licenza e
non è necessario essere vincolati a un produttore di
hardware. La gestione dei dati (vale a dire, divisio-
ne, distribuzione e replicazione dei nodi del cluster)
adotta l’HDFS in modo completamente automatico.
La gestione dell’accesso dell’utente a HDFS avvie-
&
À
2
Metodi e interfacce standard
Il funzionamento della combinazione di openMDM
e di un cluster Hadoop si può così riassumere: im-
T À
’ap-
plicazione, i dati di misurazione vengono convertiti
À YT3
standard e associati alle informazioni descrittive
(metadati). Un intermediario, come ad esempio
il server ODS Peak di Peak Solution, memorizza
À YT3
'
HDFS. Il server ha il compito di caricare o archi-
viare sulla base dell’ODS i dati che sono utilizzati
o prodotti da banchi di prova, strumenti di misura-
Fig. 2 – Hadoop è un database aziendale per informazioni provenienti dall’ambiente di prova