

















 10 / 100
10 / 100

EMBEDDED
60 • MAGGIO • 2016
LA COPERTINA DI EMBEDDED
NATIONAL INSTRUMENTS
10
ze nella pipeline, garantisce il bilanciamento della latenza
all’unione delle pipeline parallele per configurare il buffer
di sincronizzazione. In questo modo si assicura che i FIFO
nei buffer di sincronizzazione abbiano una profondità suf-
ficiente in base alla latenza massima delle pipeline. L’uti-
lity del contatore di prestazioni nel Vision Assistant stima
il tempo massimo impiegato per l’elaborazione di ciascun
fotogramma (Fig. 2), permettendo di conoscere la latenza
collettiva di tutti i blocchi nella pipeline. Gran parte dei
processori del portfolio hardware NI dispongono di un si-
stema operativo real-time. L’utilizzo di Vision Assistant
semplifica quindi la stima del tempo necessario per ese-
guire una funzione di visione.
Coloro che non hanno dimestichezza con LabVIEW, note-
ranno che conVisionAssistant si garantisce la creazione di
un progetto completamente funzionale, che include tutte
le dipendenze, come gli strumenti virtuali (VI) di trasferi-
mento, le DMA FIFO e la logica di acquisizione delle im-
magini. Un VI è simile a una funzione o a una subroutine
negli altri linguaggi di programmazione. I VI di trasferi-
mento sono necessari per trasferire i dati delle immagini
tra la logica host/acquisizione e l’FPGA. Le DMA FIFO
non coinvolgono il processore host, pertanto sono il meto-
do disponibile più veloce per trasferire grandi quantità di
dati tra il target FPGA e l’host Real-Time. La logica di ac-
quisizione dipende dal tipo di sistema di visione, se basato
sull’elaborazione inline o sulla co-elaborazione.
Vision Assistant ,inoltre, permette di creare altri VI, come
l’Host VI, che viene eseguito sul processore Real-Time, e il
VI FPGA. Si potrebbe quindi compilare il VI FPGA utiliz-
zando gli strumenti Xilinx Vivado e generare un bitstream
per la distribuzione sull’FPGA. È importante notare che il
sistema che ospita la pipeline di elaborazione dell’immagi-
ne può essere largamente categorizzato come elaborazione
inline o co-elaborazione, in base al luogo in cui risiede la
logica di acquisizione. Nell’elaborazione inline, la logica di
acquisizione è sull’FPGA, la telecamera viene configura-
ta mediante la logica di acquisizione e l’immagine viene
elaborata sull’FPGA. I risultati e l’immagine elaborata
vengono poi rispediti all’host per la valutazione e ulterio-
ri analisi. Nella co-elaborazione, la logica di acquisizione
per la telecamera è sul processore. Trasferire l’immagine
dal processore all’FPGA, rinviare poi l’immagine elaborata
dall’FPGA al processore richiede una quantità di tempo
limitato. Si può anche suddividere l’elaborazione della pi-
peline tra il processore e l’FPGA. In quanto sviluppatore di
un sistema di visione che utilizza FPGA, devi essere con-
sapevole del throughput che l’FPGA può raggiungere. Puoi
utilizzare le informazioni sul throughput e la stima delle
risorse in tempo reale per determinare quante funzioni
(blocchi IP) puoi distribuire all’FPGA. Nella co-elabora-
zione, le prestazioni del processore determinano il throu-
ghput finale. Ciò risulta valido se si utilizzano le funzioni
IP dell’FPGA che NI fornisce con Vision Development Mo-
dule, perché si tratta di funzioni completamente pipelined
che producono prestazioni migliori rispetto alla maggior
parte dei processori.
Dal prototipo alla distribuzione
L’IP di visione FPGA del Vision Development Modu-
le consente agli sviluppatori di utilizzare l’elaborazio-
ne fortemente parallela, lo strumento Xilinx Vivado
ad alto livello di sintesi (HLS), per ottenere un IP di
visione sull’FPGA completamente pipelined, a bassa
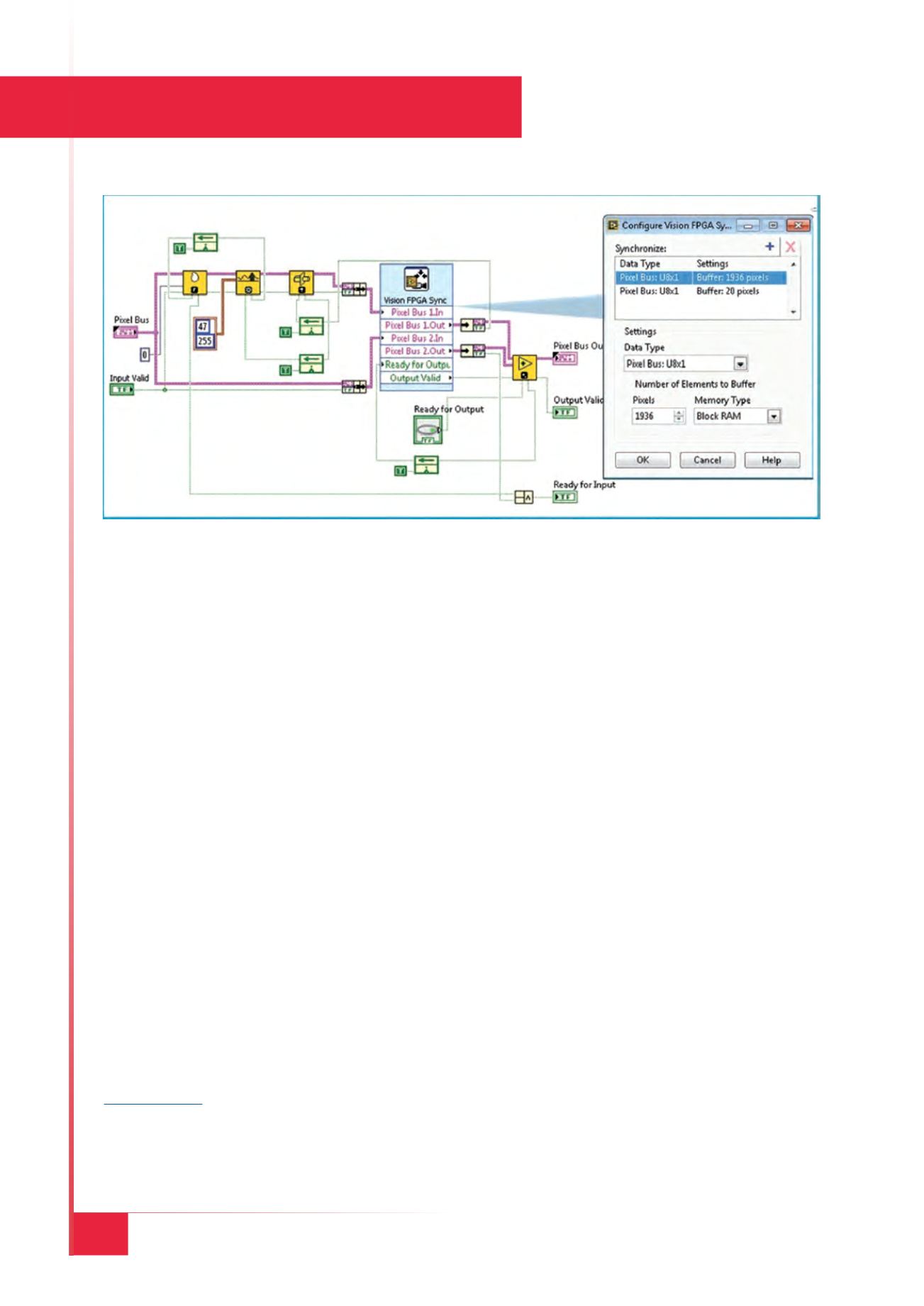
Fig. 3 - Block Diagram del VI FPGA con un nodo di sincronizzazione