







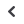










 55 / 84
55 / 84


55
MANY-CORE |
hardware
EMBEDDED
56 • maggio • 2015
eseguite in ogni ciclo di elaborazione. In genere,
la struttura di un processore many-core è forma-
ta da un certo numero di “tile” o mattonelle nelle
quali ci sono uno, due o quattro core, una me-
moria con DMA propria e un’interfaccia di rete
che collega la mattonella a un mini router locale,
che costituisce un nodo connesso in rete insieme
agli altri router e alle risorse esterne, ovvero le
periferiche e gli I/O comuni. All’inizio le matto-
nelle sono tutte asincrone e perciò il dispositivo
si può definire un Array of simple Asynchronous
Processor, o AsAP, ma poi l’algoritmo principa-
le decide come distribuire le task fra i vari core
e perciò ne attribuisce le mansioni, le risorse e
la temporizzazione in modo dinamico, dimensio-
nando tutto in funzione delle task da svolgere
e sincronizzando di volta in volta fra loro i core
che eseguono la stessa task. Per questo motivo si
parla di sistema Globally Asynchronous Locally
Synchronous (GALS), che in ogni caso consente
allo sviluppatore di impostare gli algoritmi in pa-
rallelo in forma modulare e scalabile.
Many-core sotto la torre Eiffel
Kalrayè nata a Parigi due anni fa con la missio-
ne di mettere in pratica vent’anni di studi portati
avanti dai suoi fondatori nelle università euro-
pee e dunque sperimentare e sviluppare i primi
processori many-core per applicazioni embedded,
perfezionando le tecniche di programmazione
in parallelo degli algoritmi per applicarle di-
rettamente in hardware. Come risultato è nata
l’architettura MPPA, Multi-Purpose Processing
Array, e la relativa tecnica di programmazione
MPPA AccessCore. MPPA256 di Kalray è un pro-
cessore composto da 256 core di calcolo chiama-
ti Processing Engine (PE) e 32 core di gestione
risorse, detti Resource Management (RM), inte-
grati in un chip in geometria di riga da 28 nm.
Le sue prestazioni sono calcolate in 500 GOPS
(Giga Operations Per Second) con un consumo
massimo di 5W, ossia circa 80 GOPS/W, oppu-
re 50 GFLOPS/W (operazioni in virgola mobile),
mentre le istruzioni in C/C++ sono scritte con
programmi MPPA AccessCore e sono molto lar-
ghe (VLIW, Very Long Instruction Word), perché
ciò consente di indirizzare un’unità aritmetica in
virgola mobile a doppia precisione, 16 Compute
Cluster e 4 sottosistemi I/O, ciascuno con una
propria memoria dedicata. Le comunicazioni fra i
nodi sono temporizzate da un’apposita Network-
on-Chip (NoC) con banda di ben 3,2 GByte/sec,
che decide quante e quali risorse assegnare a cia-
scun core per svolgere una particolare task, non-
ché provvedere a sincronizzare l’attività dei core
che la eseguono, in modo tale che siano sincroni
fra di loro ma asincroni rispetto agli altri core,
che nel frattempo eseguono altre task e devono
pertanto avere una diversa temporizzazione.
Fra le interfacce periferiche si possono utilizza-
re 64 I/O general-purpose, due smart Ethernet
configurabili come quattro porte 10 GbE o una
40 GbE, due canali DDR3 da 64 bit e 12,8 GB/s,
due PCIe Gen3 con 8 porte ciascuna e una NoCX
(Network-on-Chip eXpress). Il dispositivo è sca-
labile e può ospitare da 64 fino a ben 1024 core
con cui riesce a eseguire ben 8 TeraOPS, che cor-
rispondono a 5 TFLOPS. Inoltre, viene proposto
anche nella scheda preconfigurata EMB01, che
offre 700 GOPS e 230 GFLOPS e ospita una li-
breria completa di applicazioni per l’elaborazione
dei segnali video e audio. Queste schede si posso-
no anche mettere insieme e comporre così com-
puter con prestazioni scalabili e confrontabili con
quelle dei supercomputer più blasonati. La socie-
tà francese ha recentemente presentato MPPA
TurboCard2, con sopra ben 1024 core e 32 GByte
di memoria DDR, per un livello di prestazioni di
oltre 1 TFLOPS.
Fig. 4 – Kalray propone la sua tecnologia anche
sulla nuova scheda MPPA TurboCard2, con a
bordo 1024 core per un livello di prestazioni
oltre 1 TFLOPS