

















 54 / 86
54 / 86

EDA/SW/T&M
ADAS
54
- ELETTRONICA OGGI 460 - MARZO 2017
istruzioni in formato VLIW. In un singolo ciclo è possi-
bile avviare (issue) ed eseguire fino a cinque slot (una
Very Long Instruction è composta da slot). Oltre a ciò,
grazie a un set di istruzioni ottimizzato per applicazioni
di visione specializzato nell’elaborazione parallela dei
pixel a 8 o 16 bit è possibile aumentare in modo sensi-
bile le prestazioni di calcolo per gli algoritmi di visione.
I calcoli richiesti dalle applicazioni di visione artificiale
richiedono un uso intensivo dell’ampiezza di banda di
memoria a causa delle grandi dimensioni dei dati rela-
tivi all’immagine. Per eliminare i “colli di bottiglia” legati
all’accesso in memoria il processore Vision DSP preve-
de un DMA 2D integrato (iDMA) che utilizza la tecnica
scatter-gather e due banchi di RAM locali a elevata ve-
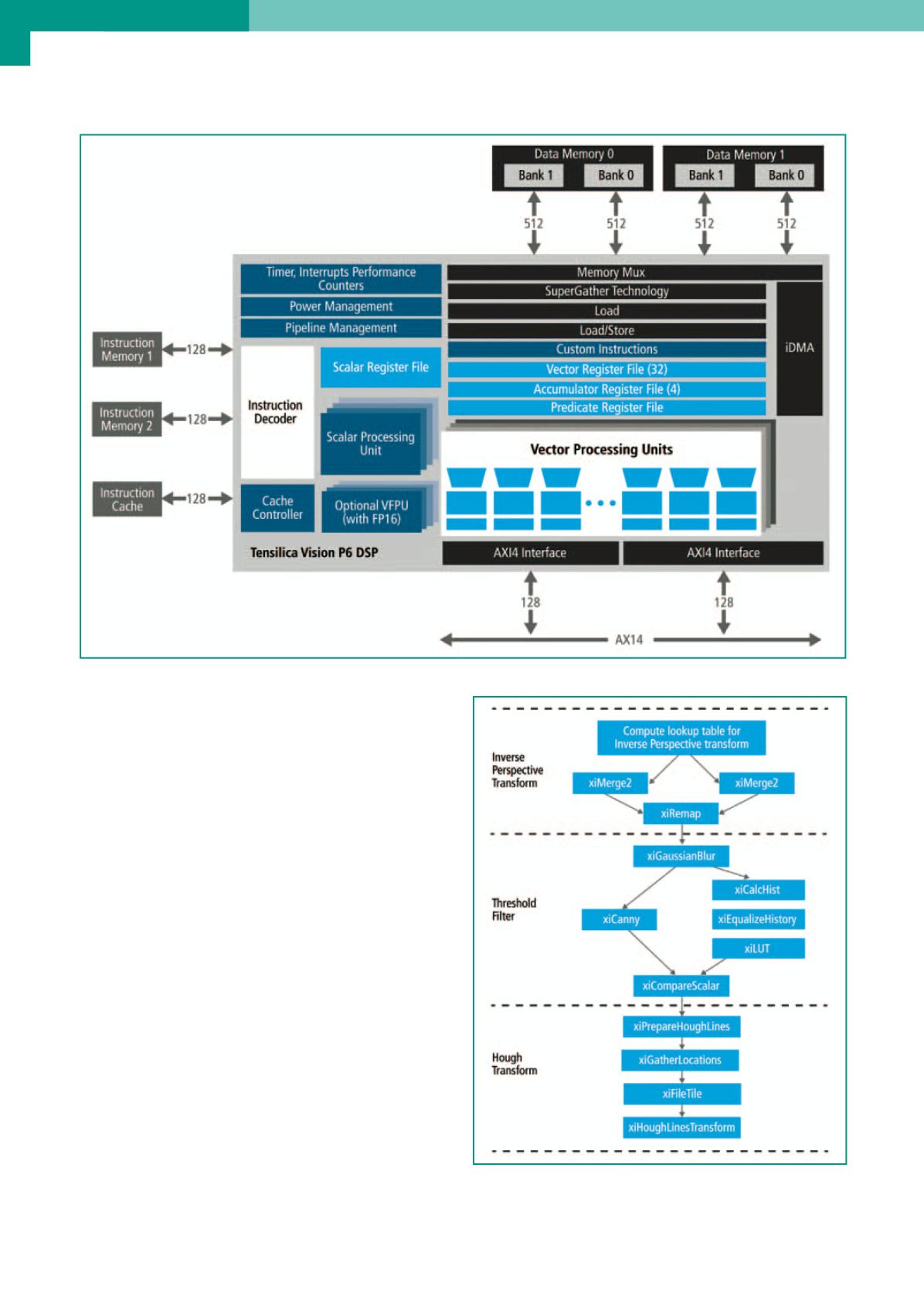
locità. Questa architettura è riportata in figura 4.
Mentre l’architettura di Vision DSP è stata progetta-
ta per supportare l’elaborazione della visione ad alte
prestazioni, l’operazione di porting di codice C gene-
rico sul DSP per sfruttarne le capacità di calcolo non
è un compito semplice. Vision DSP è corredato con un
compilatore ad alte prestazioni in grado di dedurre ed
estrarre il parallelismo dal codice C generico. Nono-
stante ciò spesso è richiesto lo sviluppo del kernel di
elaborazione della visione mediante codice intrinseco
C ottimizzato “a mano” al fine di ottimizzare le prestazio-
ni. Allo scopo di ridurre gli oneri legati al porting e al
Fig. 4 – Architettura del processore DSP Tensilica Vision di Cadence
Fig. 5 – Mappatura delle diverse fasi dell’algoritmo di rilevamento
della corsia sfruttando le funzioni presenti nella libreria XI