60
- ELETTRONICA OGGI 436 - MAGGIO 2014
DIGITAL
SoC
un approccio caratterizzato da una notevole scalabilità poi-
ché il sistema operativo che gestisce una multi-elaborazione
di tipo simmetrico è progettato in modo da poter effettuare
senza problemi il porting su un numero sempre maggiore di
core. Poiché tutti i core sono gestiti da un singolo sistema
operativo, il trasferimento dei messaggio tra i diversi core
può avvenire nella cache dei dati di primo livello (L1), con
conseguente aumento della velocità di comunicazione e
riduzione del jitter.
Con l’isolamento del core è possibile destinare un core alla
applicazioni hard real time e “difenderlo” dagli effetti degli
altri core a elevato throughput, preservano così le carat-
teristiche di basso jitter e di risposta in real time. Di tratta
in generale di un’architettura software ottimale in quanto
consente ai progettisti di scegliere quali sistemi operativi
utilizzare invece di “reinventare” software di basso livello e
soggetto ad errori per gestire più sistemi operativi. Se sin
dal principio vi sono più sistemi operativi il porting iniziale
può dar adito a qualche difficoltà, che possono essere note-
volmente ridotte partendo da un’architettura SMP.
Ottimizzare i sistemi SoC real time
a elevato throughput con SMP
Dopo un’attenta analisi delle varie alternative, la multi-ela-
borazione SMP con isolamento del core SMP è senza dubbio
la migliore architettura per ottimizzare sistemi SoC a elevato
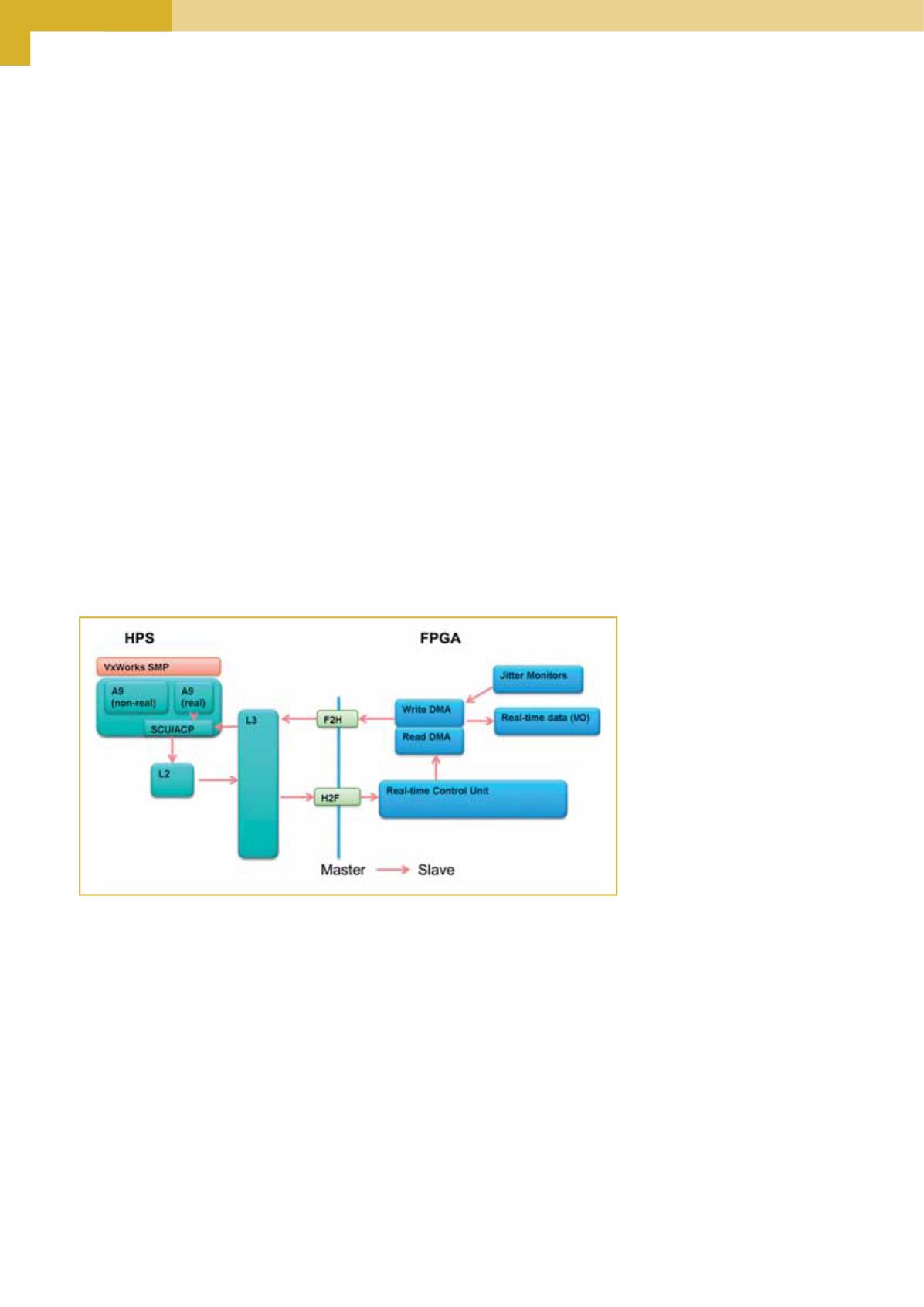
throughput operanti in real time. L’architettura che verrà
presa in considerazione è simile a quella riportata in figura
3 dove un SoC riceve i dati di I/O che vengono elaborati dai
processori e la risposta in real time, caratterizzata da bassi
valori di latenza e jitter, è resa di disponibile in uscita. Il SoC
risulta composto da più core che fanno girare simultanea-
mente altre applicazioni a elevato throughput.
In primo luogo è essenziale comprendere che una risposta
in real-time (loop time) richiede l’espletamento delle seguen-
ti operazioni:
1. Trasferimento dei nuovi dati alla memoria del sistema da
un I/O (DMA).
2. Rilevamento da parte del processore dei nuovi dati pre-
senti nella memoria del sistema (isolamento del core).
3. Copiatura dei dati in una memoria privata (memcpy).
4. Elaborazione dei dati.
5. Copiatura dei dati nella memoria di sistema (memcpy).
6. Trasferimento dei dati al dispositivo di I/O (DMA).
Poiché jitter e latenza si accumulano nel corso delle sei fasi
appena descritte, è importante procedere all’ottimizzazione
di ciascuna di esse. Utilizzando un RTOS (sistema operativo
in real time) come VxWorks con isolamento del core, la
risposta all’operazione di polling/interrupt (ovvero quando
il core riceve una richiesta di interruzione attiva il ciclo di
polling per individuare la periferica richiedente) può avve-
nire nel range del nanosecondo (fase 2). L’elaborazione dei
dati è tipica dell’applicazione e il
tempo richiesto è facilmente pre-
vedibile (fase 4). L’attenzione dei
progettista è quindi essenzialmen-
te rivolta alle fasi 1, 3, 5 e 6 (DMA
e copiature in memoria – memcpy).
Per trasferire i dati è possibile uti-
lizzare due modalità: con o senza la
coerenza della cache. L’adozione
dell’una o dell’altra metodologia
ha conseguenze molto diverse su
DMA e memcpy. Sebbene l’utilizzo
della porta ACP (ARM Cache Cohe-
rency Port) comporti un percorso
più lungo per il DMA, il processo-
re deve solamente accedere alla
cache di primo livello (L1) per
ottenere il dato trasferito. Il tempo
richiesto per la copiature nella
memoria (memcpy) è quindi molto più breve se si sfrutta la
coerenza della cache e rappresenta il fattore che contribu-
isce in misura maggiore al lieve degrado delle prestazioni
del trasferimento DMA. Ne consegue che il trasferimento
effettuato sfruttando la coerenza della cache dà luogo a una
latenza molto inferiore e a un jitter più ridotto, grazie alla
possibilità di accedere direttamente alla cache.
Un esempio pratico
È possibile dimostrare il funzionamento di un sistema com-
pleto sfruttando un progetto di riferimento implementato
con un kit di sviluppo per i SoC FPGA della serie Cyclone V
Fig. 3 – Progetto di riferimento sperimentale


