Le reti neurali possono essere classificate come un insieme di algoritmi modellati liberamente sul cervello umano che sono in grado di “apprendere” incorporando nuovi dati. Infatti, si possono derivare molti molti vantaggi dallo sviluppo di modelli di reti neurali progettati specificamente, che sono “efficienti dal punto di vista computazionale”. Tuttavia, per garantire l’efficacia del vostro modello, è necessario considerare diversi requisiti fondamentali.
Un aspetto critico da considerare quando si implementano gli acceleratori di inferenza (o nella fattispecie, gli acceleratori hardware in generale) riguarda il modo in cui si accede alla memoria. Nel contesto dell’inferenza per l’apprendimento automatico (ML), bisogna considerare in particolare il modo in cui archiviamo sia i pesi che i valori di attivazione intermedi. Negli ultimi anni, sono state utilizzate diverse tecniche con vari gradi di successo. Gli impatti delle relative scelte architettoniche sono significativi:
- Latenza: gli accessi alla memoria L1, L2 e L3 presentano una latenza relativamente bassa. Se i pesi e le attivazioni associati alla successiva operazione sui grafi vengono memorizzati su cache, è possibile mantenere livelli ragionevoli di efficienza. Tuttavia, se è necessario recuperare dati da una DDR esterna, si produrrà un blocco della sequenza, con impatti previsti sulla latenza e sull’efficienza.
- Consumo di potenza: il costo energetico dell’accesso alla memoria esterna è di almeno un ordine di grandezza superiore rispetto agli accessi alla memoria interna.
- Saturazione computazionale: in generale, le applicazioni sono limitate dalle risorse di calcolo o dalla memoria. Ciò può impattare sui protocolli GOP/TOP ottenibili in un determinato paradigma di inferenza, e in alcuni casi, tale impatto potrebbe essere molto significativo. Si ottiene meno valore aggiunto con un motore di inferenza in grado di ottenere prestazioni di picco da 10 TOP se le prestazioni reali durante l’esecuzione sulla vostra rete specifica sono di 1 TOP.
- Per fare un ulteriore passo in avanti, tenete presente che il costo energetico dell’accesso alla SRAM interna (noto come BRAM o UltraRAM per coloro che hanno familiarità con i SoC di Xilinx) in un moderno dispositivo Xilinx è dell’ordine dei picojoule, circa due ordini di grandezza in meno rispetto al costo energetico dell’accesso alla DRAM esterna.
Come esempio di architettura, possiamo considerare l’unità TPUv1. Quest’ultima incorpora un’unità MAC 65.536 INT8 insieme a 28 MB di memoria su chip per archiviare le attivazioni intermedie. I pesi sono recuperati dalla DDR esterna. Le prestazioni teoriche di picco dell’unità TPUv1 sono pari a 92 TOPS.
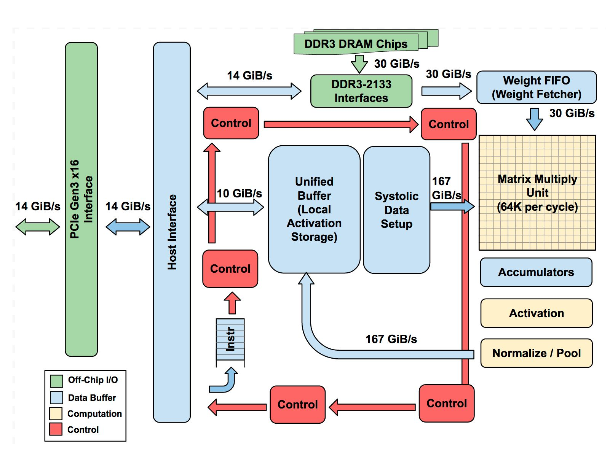{kind=link}
Figura 1: Architettura dell’unità TPUv1
Riferimento: Jouppi et al. 2017, https://arxiv.org/ftp/arxiv/papers/1704/1704.04760.pdf
L’unità TPU è un esempio di acceleratore tensoriale molto generalizzato che utilizza un compilatore complesso per pianificare le operazioni sui grafi. La TPU ha mostrato un’ottima resa di efficienza per carichi di lavoro specifici (riferimento CNN0 a 86 TOPS). Tuttavia, il rapporto tra la potenza computazionale e il riferimento di memoria per le reti CNN è inferiore rispetto a quello delle architetture MLP e LSTM e possiamo osservare che questi carichi di lavoro specifici sono legati alla memoria. Anche la rete CNN1 mostra prestazioni modeste (14,1 TOPS) come risultato diretto dei blocchi della sequenza che si verificano quando occorre caricare nuovi pesi nell’unità della matrice.
{kind=link}
Figura 2: Limiti di prestazioni per varie topologie di rete con un’unità TPUv1
Riferimento: Jouppi et al. 2017, https://arxiv.org/ftp/arxiv/papers/1704/1704.04760.pdf
L’architettura delle reti neurali ha un impatto significativo sulle prestazioni, e i valori prestazionali di picco sono scarsamente significativi nell’ambito della selezione di una soluzione di inferenza, a meno che non sia possibile ottenere livelli elevati di efficienza per i carichi di lavoro specifici che è necessario accelerare. Oggi, molti fornitori di SoC, ASSP e GPU continuano a promuovere riferimenti di prestazioni per i modelli classici di classificazione delle immagini come LeNet, AlexNet, VGG, GoogLeNet e ResNet. Tuttavia, il numero di casi d’uso reali per l’attività di classificazione delle immagini è limitato e spesso tali modelli sono utilizzati solo come estrattore di funzionalità di back-end per attività più complesse come il rilevamento e la segmentazione degli oggetti.
Esempi più realistici di modelli utilizzabili nel mondo reale riguardano il rilevamento e la segmentazione degli oggetti. In che modo ciò si correla con la constatazione che dovete cercare di trovare riferimenti IPS ufficiali per reti quali YOLOv3 e SSD, malgrado molti dispositivi su semiconduttore siano commercializzati con prestazioni offerte di 10 TOP? Ironicamente, suppongo che questo non sia un problema se avete semplicemente bisogno di effettuare operazioni grep su foto su cloud storage per una foto del vostro gatto:
{kind=link}
Non c’è da meravigliarsi che molti sviluppatori trovino che il loro primo “approccio” alla progettazione di un prodotto abilitato all’intelligenza artificiale non soddisfi i requisiti di prestazioni, costringendoli a migrare verso un’architettura diversa nel mezzo del ciclo di progettazione. Ciò è particolarmente arduo se comporta la ridefinizione dell’architetta sia dell’hardware della scheda base SOM che del software. Si scopre che un motivo chiave che spinge a scegliere i SoC di Xilinx è che, a differenza delle soluzioni della concorrenza, le soluzioni Xilinx per l’inferenza scalano direttamente di oltre un ordine di grandezza in termini di prestazioni, mantenendo lo stesso processore e le stesse architetture per l’accelerazione dell’inferenza.
Nel 2017, un team di ricercatori Google ha presentato una nuova classe di modelli pensati per le applicazioni mobili. (Howard et al, “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications” https://arxiv.org/pdf/1704.04861.pdf). Il vantaggio delle reti MobileNet è stato la notevole riduzione degli oneri computazionali, pur mantenendo livelli elevati di precisione. Una delle principali innovazioni impiegate nelle reti MobileNet è la convoluzione separabile per profondità. Per quanto riguarda la convoluzione classica, ogni canale di ingresso ha un impatto su ogni canale di uscita. Se abbiamo 100 canali di ingresso e 100 canali di uscita, sono presenti 100×100 percorsi virtuali. Tuttavia, per la convoluzione in base alla profondità, dividiamo lo strato di convoluzione in 100 gruppi ottenendo di conseguenza solo 100 tracciati. Ciascun canale di ingresso è collegato solo a 1 canale di uscita, con un conseguente risparmio di notevoli risorse di calcolo.
{kind=link}
Figura 4: Connettività nella convoluzione classica e in base alla profondità
Riferimento: Song Yao, Hotchips HC30, Session 8: https://www.hotchips.org/archives/2010s/hc30/
Una conseguenza di tutto ciò è che per le reti MobileNet il rapporto tra risorse computazionali e memoria si è ridotto, con l’implicazione che la larghezza di banda di memoria e la latenza svolgono un ruolo più importante per raggiungere una velocità effettiva elevata.
Purtroppo, le reti efficienti dal punto di vista computazionale non sono necessariamente compatibili con l’hardware. Idealmente, la latenza cala con proporzione lineare con la riduzione delle operazioni a virgola mobile (FLOP). Tuttavia, come si suol dire, non esiste un pasto gratuito. Si consideri ad esempio il confronto seguente, che mostra che il carico di lavoro computazionale di una rete MobileNetv2 è meno di un decimo rispetto al carico utile di una ResNet50, tuttavia, la latenza non segue lo stesso andamento.
{kind=link}
Figura 5: Numero di operazioni e latenza in una rete MobileNet e ResNet50 a confronto
Riferimento: Song Yao, Hotchips HC30, Session 8: https://www.hotchips.org/archives/2010s/hc30/
Nell’analisi precedente, possiamo osservare che la latenza non si riduce di 12 volte in proporzione alla riduzione delle operazioni in virgola mobile.
Quindi, come risolviamo questo problema? Se confrontiamo il rapporto tra la comunicazione all’esterno del chip e le risorse di calcolo, vediamo che una rete MobileNet mostra un profilo molto diverso rispetto a una rete VGG. Per quanto riguarda gli strati di convoluzione DWC, possiamo vedere che il rapporto è pari a 0,11. L’acceleratore è ora legato alla memoria e quindi raggiunge livelli più bassi di efficienza perché molti elementi della matrice di PE giacciono come server “oscuri” in un data center, consumando energia e area su chip, senza eseguire alcun lavoro utile.
{kind=link}
Figura 6: Rapporto tra comunicazione e risorse di calcolo (CTC) in una rete VGG16 e in una rete MobileNetv1
Riferimento: Song Yao, Hotchips HC30, Session 8: https://www.hotchips.org/archives/2010s/hc30/
Quando Xilinx introdusse l’unità DPUv1, questa era progettata per accelerare (tra le altre operazioni) la convoluzione convenzionale. Quest’ultima richiede una riduzione per canale relativa all’ingresso. Tale riduzione è più ottimizzata per l’inferenza hardware perché aumenta il rapporto tra le risorse di calcolo e memoria per le operazioni di calcolo/attivazione. Considerando il costo energetico delle operazioni di calcolo rispetto alla memoria, tale aspetto è molto positivo. Questo è uno dei motivi per cui le installazioni di reti basate su ResNet sono così predominanti nelle applicazioni ad alte prestazioni: il rapporto tra le risorse di calcolo e la memoria è maggiore con le reti ResNet rispetto a molte dorsali storiche.
Le convoluzioni basate sulla profondità non comportano simili riduzioni per canale. Le prestazioni della memoria diventano molto più importanti.
Per l’inferenza, in genere confondiamo la convoluzione DWC con la convoluzione PWC e memorizziamo le attivazioni DWC nella memoria su chip, quindi avviamo immediatamente la convoluzione PWC 1×1. Nel contesto dell’unità DPU originale, non esisteva un supporto hardware specializzato per le convoluzioni DWC, con il risultato che l’efficienza era subottimale:
{kind=link}
Figura 7: Operazioni e latenza in una rete MobileNet e in una rete ResNet50 a confronto – DPUv1 (nessun supporto nativo alla convoluzione DWC)
Riferimento: Song Yao, Hotchips HC30, Session 8: https://www.hotchips.org/archives/2010s/hc30/
Per accelerare le prestazioni della convoluzione DWC nell’hardware, abbiamo modificato la funzionalità degli elementi PE (elementi di elaborazione) nell’unità DPU di Xilinx e abbiamo fuso l’operatore DWC con l’operatore CONV basato sui punti. Dopo l’elaborazione di un pixel di uscita nel primo livello, l’attivazione viene immediatamente posta in sequenza alla convoluzione 1×1 (attraverso la memoria BRAM sul chip nella DPU) senza scrivere sulla DRAM. Utilizzando questa tecnica specialistica possiamo aumentare notevolmente l’efficienza delle esecuzioni sull’unità DPU delle reti MobileNet.
{kind=link}
Figura 8: Una unità DPUv2, elemento di elaborazione specialistica dell’operatore DWC
Riferimento: Song Yao, Hotchips HC30, Session 8: https://www.hotchips.org/archives/2010s/hc30/
Con questa architettura modificata dell’unità DPUv2 siamo stati in grado di offrire un notevole miglioramento in termini di efficienza dell’inferenza MNv1. Inoltre, aumentando la quantità di memoria su chip, possiamo aumentare ulteriormente l’efficienza in modo da eguagliare i nostri risultati con una rete ResNet50. Tutto ciò è stato ottenuto utilizzando la stessa CPU e la stessa architettura hardware!
{kind=link}
Figura 9: Latenza di esecuzione su reti MobileNet e ResNet50, con unità DPUv1 e DPUv2 a confronto (supporto alla convoluzione DWC)
Riferimento: Song Yao, Hotchips HC30, Session 8: https://www.hotchips.org/archives/2010s/hc30/
Un evento comune consiste nell’ottimizzazione dell’hardware di inferenza e del modello di rete neurale in isolamento l’uno rispetto all’altro. Tenete presente che le reti vengono generalmente addestrate utilizzando delle GPU e operano nelle regioni periferiche su SoC o GPU con un’architettura notevolmente diversa. Per ottimizzare realmente le prestazioni, dobbiamo adattare l’hardware per adottare in modo efficiente i modelli che non sono necessariamente compatibili con l’hardware. In questo contesto, il principale vantaggio dell’hardware adattabile è che i dispositivi Xilinx offrono un’opportunità unica per continuare a co-evolvere sia software che hardware dopo il rilascio dei dispositivi.
Per fare un ulteriore passo in avanti, considerate le implicazioni del seguente articolo innovativo, intitolato “The Lottery Ticket Hypothesis” (Frankle & Carbin, 2019 https://arxiv.org/pdf/1803.03635.pdf). In questo articolo (uno dei due che orgogliosamente si è aggiudicato il premio all’ICLR2019) gli autori “formulano l’ipotesi” che “le reti feed-forward inizializzate casualmente contengano sottoreti (le carte vincenti) che – se addestrate in isolamento – raggiungono una precisione di test paragonabile alla rete originale in un numero analogo di iterazioni (addestramento)”. E ‘chiaro allora che il futuro per le tecniche di riduzione delle dimensioni delle reti rimane luminoso, e tecniche quali AutoML risulteranno ben presto come “carte vincenti” per noi all’interno del processo di rilevazione e di ottimizzazione delle reti.
È anche vero che la soluzione migliore ad oggi per garantire implementazioni efficienti e ad alta precisione a bordo rete rimane la riduzione dei canali delle dorsali classiche. Mentre queste ultime possono essere inefficienti ai fini dell’implementazione, l’eliminazione di tali canali semi-automatizzati può fornire risultati estremamente efficienti (si faccia riferimento all’esempio VGG-SSD di Xilinx). Vorrei quindi formulare l’ipotesi che la “carta vincente” possa oggi essere trovata semplicemente selezionando per il vostro prossimo progetto un’architettura di inferenza che sia a prova di futuro, e che consenta di avvalersi delle architetture di rete e delle tecniche di ottimizzazione future garantendo la longevità del prodotto per i vostri clienti.
{kind=link}
Sono molto ottimista sul fatto che le possibilità abbonderanno quando la ricerca futura che scaturirà dall’articolo “The Lottery Ticket Hypothesis” ci porterà a una nuova generazione di tecniche di riduzione delle dimensioni delle reti per ottenere guadagni di efficienza ancora maggiori. Inoltre, non è solo la mia intuizione che suggerisce che solo l’hardware adattabile, offrendo una scalabilità multi-dimensionale, vi fornirà un mezzo per aggiudicarvi il premio. Procuratevi un kit ZCU104, scaricate Vitis-AI, e iniziate oggi stesso il vostro viaggio nel futuro dell’intelligenza artificiale.