

















 63 / 84
63 / 84

63
EMBEDDED
MAGGIO
HYPERVISOR |
SOFTWARE
Debug “stop mode”: si ferma tutto
Quando si passa al debugging controllato ad
hardware, il debugger è collegato direttamente
alla CPU mediante opportuni pin (Figura 4). Il
debugger fa uso di questi pin, tipicamente JTAG,
per controllare la CPU stessa, per esempio fer-
mandola, attivando singoli step di programma,
leggendo i registri o la memoria. Tuttavia ciò si-
À
i processi, i guest e naturalmente l’hypervisor,
vengono fermati quando scatta un breakpoint.
In questo modo non vengono serviti più gli inter-
rupt, non girano più i protocolli di comunicazione
e non si hanno più cambi di macchina virtuale, di
processi o di task. La CPU è effettivamente fer-
ma, per questo si chiama stop mode.
Quando si trova in questo stato la CPU “vede”
solo i componenti attualmente aperti via MMU,
cioè un solo guest (quello che sta girando al mo-
mento nella CPU) e un solo processo (quello at-
tivo al momento nel guest). Tutti i registri e gli
accessi alla memoria fanno riferimento a questo
contesto. La CPU non ha alcun accesso ad altre
macchine virtuali o ad altri processi. Anche un
debugger hardware accede al sistema tramite la
CPU e pertanto all’inizio è soggetto alle stesse re-
strizioni: può solo “vedere” la situazione corrente.
Però è capace di fare molto più di questo. Gra-
À
MMU, può anche leggere direttamente lo spazio
À
-
D 0À
1% '
tutti i simboli di debug che appartengono ai pro-
cessi e ai guest sono relativi a indirizzi virtuali
G
À
@
molto utile per cominciare. Inoltre gli sviluppato-
ri vogliono vedere tutto: l’hypervisor, tutti i guest
e tutti i loro processi, tutto quanto e tutto insie-
me! Questo certamente non si può fare in run
mode per i motivi sopra citati, ma si può fare in
stop mode e questa è la vera forza di tale metodo.
Perché il debugger possa vedere tutto, al di là
dello stato corrente, è necessario che abbia una
maggior conoscenza del sistema, cioè dimostri
una “consapevolezza” (awareness). Servono una
“hypervisor awareness”, una “OS awareness” per
ciascun guest e una “MMU awareness” sia per
l’hypervisor sia per ciascun guest, tutti elementi
che possono variare in modo considerevole. Poi-
ché il debugger è ora consapevole della struttura
del sistema, può leggere la lista dei guest e dei
processi, come pure le loro tabelle MMU di siste-
ma. Forte di questa conoscenza il debugger può
eseguire la “MMU table walk” (traduzione degli
À 1
-
dirizzo virtuale di un guest o di un processo, cioè
superare l’MMU hardware e leggere i rispettivi
À %
implementando questo metodo che il debugger
può accedere a tutti gli indirizzi che appartengo-
no a tutti i guest e a tutti i processi, senza preoc-
À %
E tutto questo viene fatto contemporaneamente!
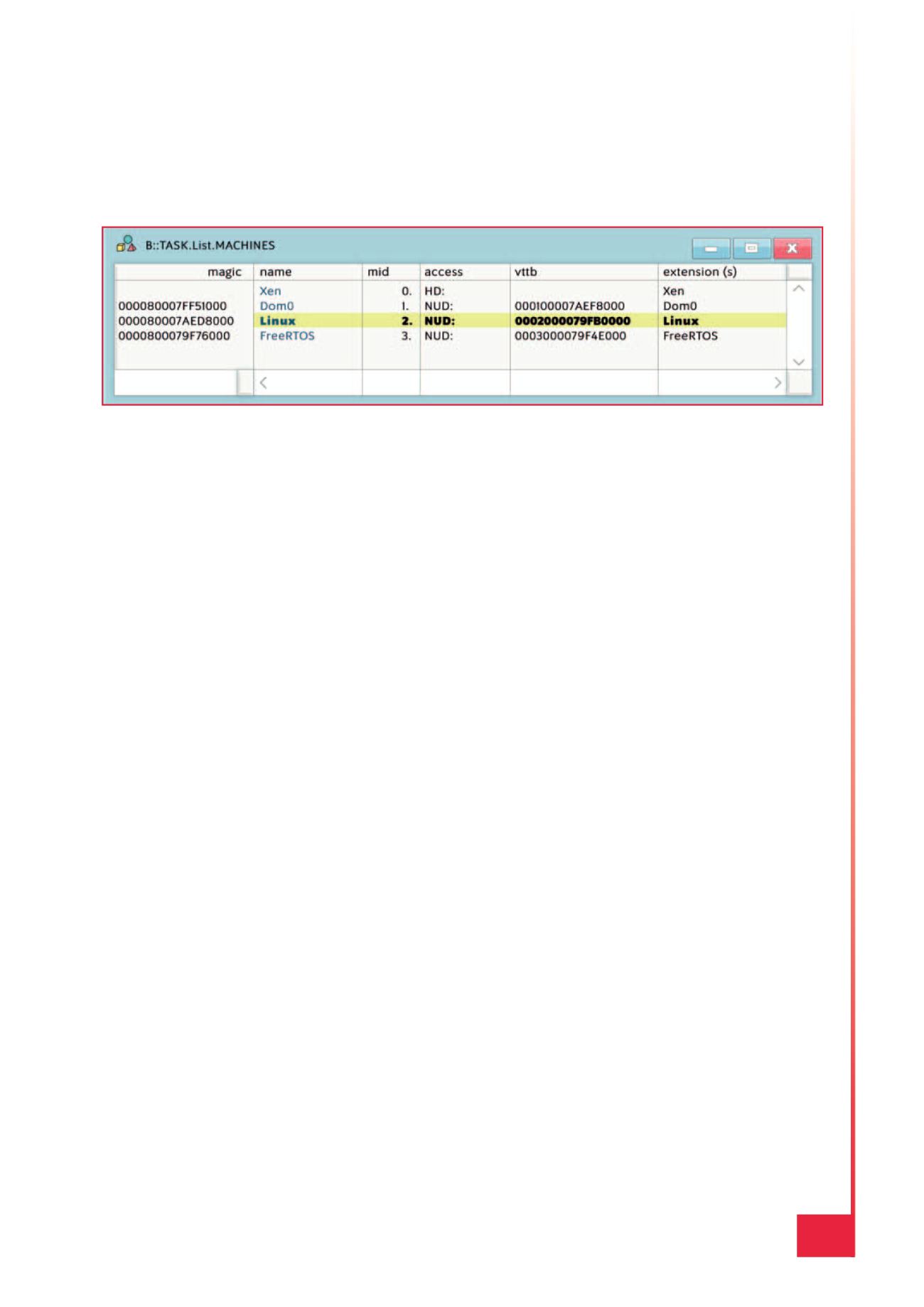
Il debugger ha bisogno di una “awareness”
Così il debugger riesce ad accedere a un sistema
target composto da un hypervisor e da più sistemi
operativi guest. Ogni macchina ha il proprio set di
registri, traslazioni MMU, processi, simboli, bre-
akpoint, ecc. Il debugger deve essere in grado di
operare con ciascuna di queste macchine, e questo
si applica sia allamacchina “reale” (l’hypervisor) sia
a tutti i sistemi guest virtualizzati, come se fossero
macchine reali. Naturalmente deve saper operare
su tutte le macchine contemporaneamente. Per
questo scopo si usa la sopra citata awareness. Una
hypervisor awareness deve essere predisposta in
modo dedicato per ciascun hypervisor e determina
Fig. 5 – Il debugger “conosce” l’hypervisor e le macchine guest