L’adozione di tecnologie per la visione artificiale (CV – Computer Vision) si sta diffondendo rapidamente in applicazioni di guida autonoma. Gli algoritmi di visione artificiale sono di tipo compute-intensive, ovvero richiedono una notevole mole di calcoli. L’esecuzione di questi algoritmi spesso richiede DSP specializzati ad alte prestazioni o GPU per garantire l’esecuzione in tempo reale abbinata a un elevato livello di flessibilità. La necessità di mappare un algoritmo di visione allo stato dell’arte frutto di ricerche teoriche in un software ottimizzato in termini di prestazioni che deve girare in real time su una piattaforma embedded è un compito decisamente impegnativo per tutti gli sviluppatori di algoritmi.
{kind=link}
Nel corso di questo articolo verrà descritta l’implementazione di un algoritmo che rileva il superamento della corsia (una delle tante funzionalità presenti nei sistemi avanzati di assistenza alla guida – ADAS) per illustrare il flusso di sviluppo software di un’applicazione di visione artificiale e le problematiche che devono affrontare gli sviluppatori di questi algoritmi per ottenere prestazioni elevate a fronte di risorse di sistema limitate.
Grazie a una libreria per visione artificiale ricca di funzionalità e ottimizzata in termini di prestazioni è possibile ridurre a poche settimane il ciclo di sviluppo del software, ottenendo un codice ottimizzato per DSP in grado di supportare il calcolo vettoriale ad alte prestazioni in tempo reale a partire da codice C funzionale generico. Nella parte finale dell’articolo saranno illustrare le tecniche utilizzate per ottimizzare il software per visione artificiale che sfruttano le caratteristiche avanzate integrate nella famiglia di DSP a elevate prestazioni di Cadence Tensilica Vision.
Flusso di sviluppo software per applicazioni CV in sistemi embedded
Lo sviluppo di applicazioni di visione artificiale per sistemi embedded è spesso vincolato dalle risorse hardware e di elaborazione disponibili in questi sistemi, nonché dal fatto che questi ultimi devono funzionare in tempo reale. Gli sviluppatori devono essere in grado di ottimizzare le prestazioni delle loro applicazioni rispettando i vincoli imposti dai sistemi. Le metriche per la misura delle prestazioni, in termini di velocità di elaborazione dati e accuratezza, devono essere attentamente bilanciate con altri parametri di ottimizzazione, come ad esempio dimensioni del codice e dei dati, occupazione di memoria (memory footprint), tempi di latenza e consumi di potenza.
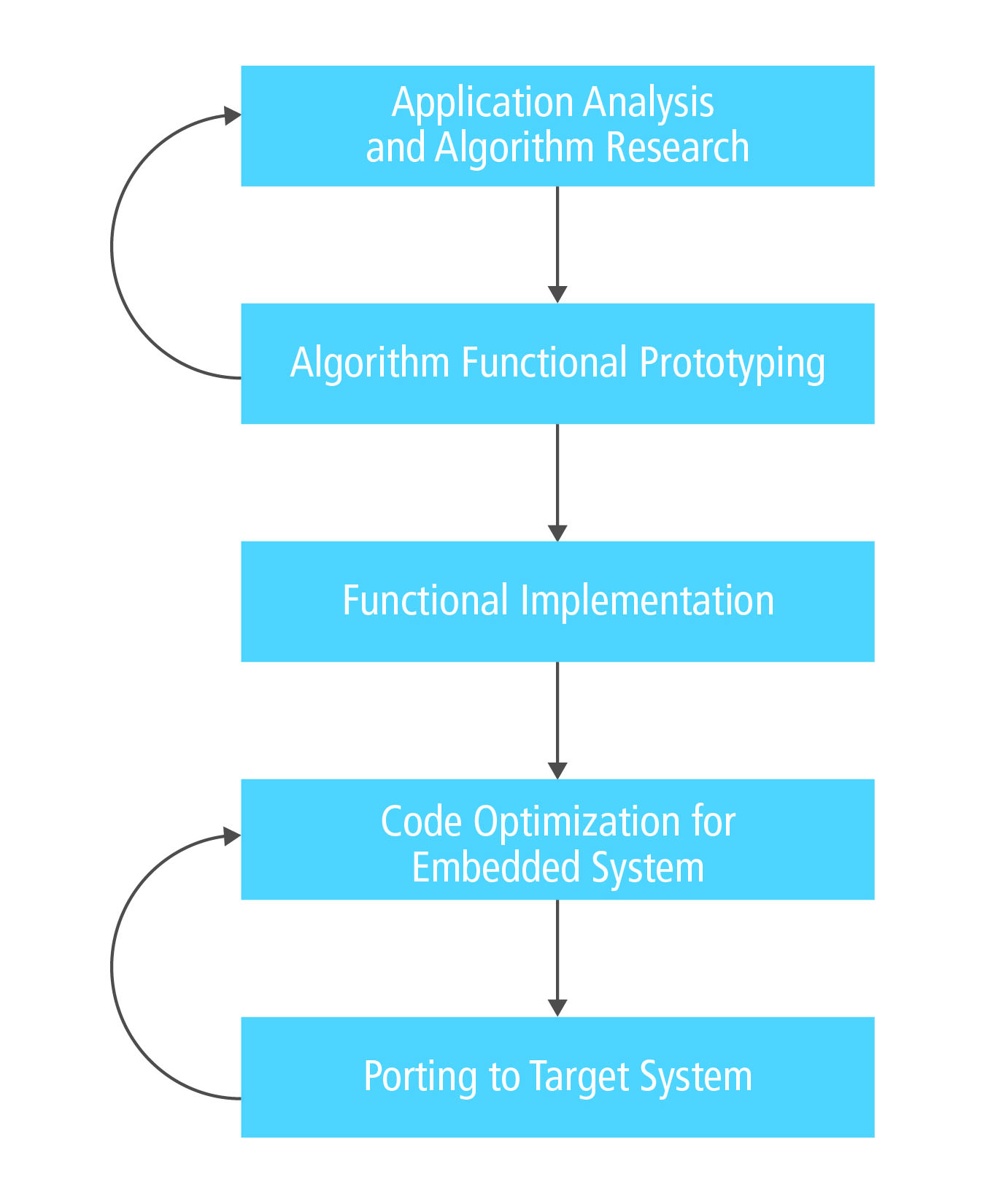
Il processo di sviluppo di un’applicazione di visione embedded risulta composto da cinque fasi, come visibile in figura 1.
Nel corso di questo articolo saranno brevemente illustrate le caratteristiche e le problematiche da affrontare nello sviluppo di algoritmi per il rilevamento del superamento della corsia. Quindi l’attenzione sarà focalizzata sull’implementazione e ottimizzazione degli algoritmi relativi alle fasi 3 e 4 utilizzando DSP della famiglia Tensilica Vision e la libreria XI per applicazioni di visione artificiale ottimizzata per DSP.
{kind=link}
Implementazione di un algoritmo LDWS robusto
Il sistema LDWS (Lane-Departure Warning System – avvertimento del superamento della propria corsia di marcia) è una funzione essenziale di un sistema ADAS per la guida autonoma. Nella quasi totalità dei sistemi LDWS è prevista una fase iniziale di rilevamento del segno che delimita la corsia che può essere generalizzata e semplificata seguendo questi passi fondamentali:
- Estrazione delle caratteristiche della strada.
- Post-elaborazione per la rimozione dei valori erratici (in pratica molto al di fuori della norma).
- Filtraggio del tracciamento (tracking) e data fusion (aggregazione dei dati).
L’accuratezza e l’affidabilità di un sistema LWDS dipende dalla precisione e dalla robustezza dell’algoritmo impiegato per il rilevamento della corsia che deve prendere in considerazione un gran numero di fattori – forme della corsia, non uniformità della struttura del piano della superficie stradale, condizioni di illuminazione, zone d’ombra, ostruzioni e via dicendo – mentre effettua il calcolo in real time mentre il veicolo è in movimento ad alta velocità. Nel corso dell’articolo verrà proposto un algoritmo per il rilevamento del segno della corsia che prevede numerose fasi di elaborazione della visione artificiale per migliorare l’affidabilità del rilevamento stesso.
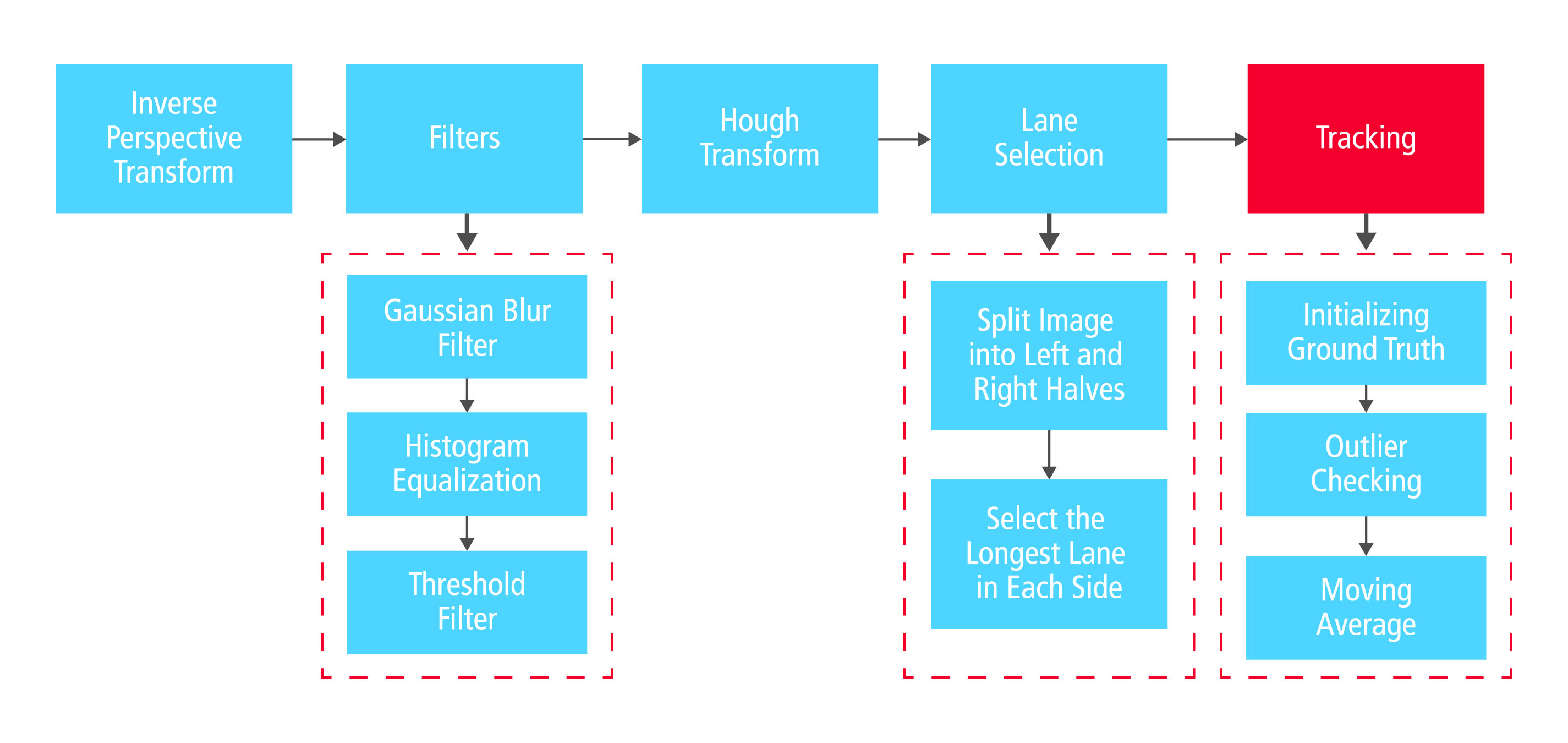
Come visibile nelle figure 2 e 3, viene utilizzato un fotogramma di un’immagine ripresa da una telecamera che si trova a bordo del veicolo per ricavare una ROI (Region of Interest) che contiene i segni che delimitano la corsia. Quindi viene eseguita una trasformazione prospettica inversa basata sui parametri della telecamera per far sì che i segni che delimitano la corsia di trovino in una posizione relativamente parallela all’interno dell’immagine. A questo punto vengono effettuate alcune operazioni di miglioramento dell’immagine tra cui filtraggio, equalizzazione e impostazione delle soglie, finalizzate a ridurre il rumore.
Seguono quindi le fasi di rilevamento dei segni della corsia e di selezione che sfruttano la trasformata di Hough. Infine il rilevamento viene migliorato mediante tecniche di Tracciamento inter-frame (tra due fotogrammi). L’algoritmo è stato prototipato in MATLAB (MathWorks) al fine di convalidarne la funzionalità e le caratteristiche di robustezza.
{kind=link}
Fig. 3 – Operazioni effettuate per aumentare la robustezza dell’algoritmo per il rilevamento della corsia
Mentre la prototipazione dell’algoritmo in MATLAB è un’operazione relativamente semplice, il porting (in altre parole il trasferimento) delle diverse fasi dell’algoritmo in un sistema embedded real time non lo è affatto. A causa della complessità dell’algoritmo, il codice C risultante e che elabora in modo sequenziale i pixel dell’immagine non è in grado di garantire la velocità richiesta da un’applicazione real time, a meno che non venga eseguito su un server ad alte prestazioni che, ovviamente, non può essere utilizzato in un sistema embedded a causa delle dimensioni e dei consumi. Per risolvere il problema è stato utilizzato un DSP della famiglia Tensilica Vision (disponibile sotto forma di IP) integrato in un sistema di prototipazione basato su FPGA.
Questo processore sfrutta un’architetture DSP ad alte prestazioni che supporta elaborazioni e operazioni di load/store su un data set SIMD (Single Instruction Multiple Data) vettoriale a 64 vie. L’architettura codifica e invia le istruzioni in formato VLIW. In un singolo ciclo è possibile avviare (issue) ed eseguire fino a cinque slot (una Very Long Instruction è composta da slot). Oltre a ciò, grazie a un set di istruzioni ottimizzato per applicazioni di visione specializzato nell’elaborazione parallela dei pixel a 8 o 16 bit è possibile aumentare in modo sensibile le prestazioni di calcolo per gli algoritmi di visione.
I calcoli richiesti dalle applicazioni di visione artificiale richiedono un uso intensivo dell’ampiezza di banda di memoria a causa delle grandi dimensioni dei dati relativi all’immagine. Per eliminare i “colli di bottiglia” legati all’accesso in memoria il processore Vision DSP prevede un DMA 2D integrato (iDMA) che utilizza la tecnica scatter-gather e due banchi di RAM locali a elevata velocità. Questa architettura è riportata in figura 4.
{kind=link}
Mentre l’architettura di Vision DSP è stata progettata per supportare l’elaborazione della visione ad alte prestazioni, l’operazione di porting di codice C generico sul DSP per sfruttarne le capacità di calcolo non è un compito semplice. Vision DSP è corredato con un compilatore ad alte prestazioni in grado di dedurre ed estrarre il parallelismo dal codice C generico. Nonostante ciò spesso è richiesto lo sviluppo del kernel di elaborazione della visione mediante codice intrinseco C ottimizzato “a mano” al fine di ottimizzare le prestazioni. Allo scopo di ridurre gli oneri legati al porting e al ciclo di ottimizzazione è stato implementata una vasta gamma di kernel di elaborazione della visione in una libreria software simile a OpenCV denominata XI.
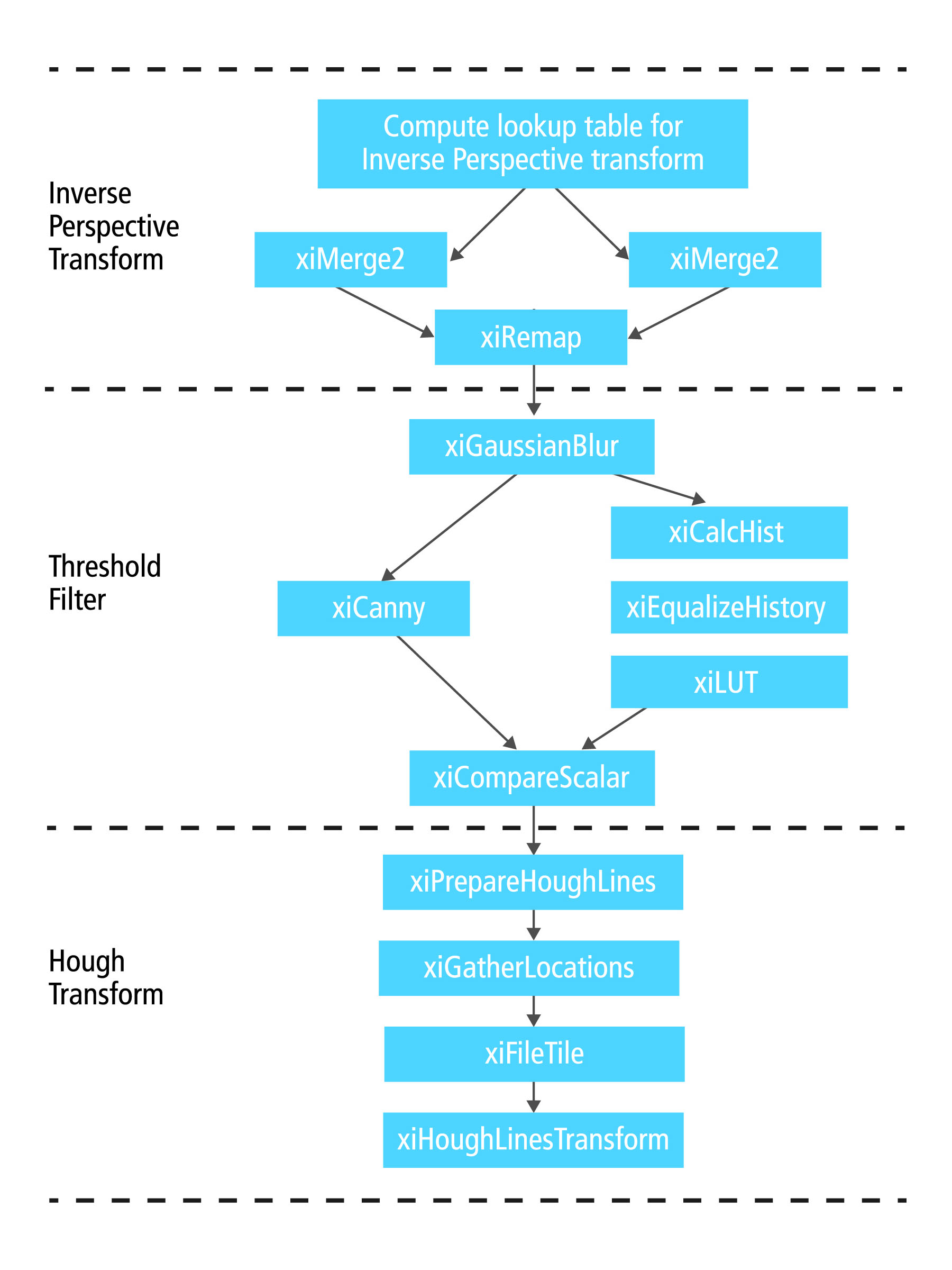
In questo caso è stato utilizzato un gran numero di funzioni della libreria XI in tutte le fasi di elaborazione per effettuare la trasformazione della prospettiva, il filtraggio dell’immagine, l’equalizzazione, l’impostazione di soglie, la rilevazione dei bordi mediante il metodo Canny, la trasformata di Hough e così via come mostrato in figura 5.
L’impiego delle funzioni della libreria XI permette di ridurre gli oneri legati al porting e all’ottimizzazione dell’algoritmo per il rilevamento della corsia nei DSP Vision P5/P6. Le prestazioni di elaborazione in real time richieste possono essere ottenute nel simulatore del set di istruzioni (ISS – Instruction Set Simulator) nell’arco di uno o due mesi.
{kind=link}
Fig. 5 – Mappatura delle diverse fasi dell’algoritmo di rilevamento della corsia sfruttando le funzioni presenti nella libreria XI
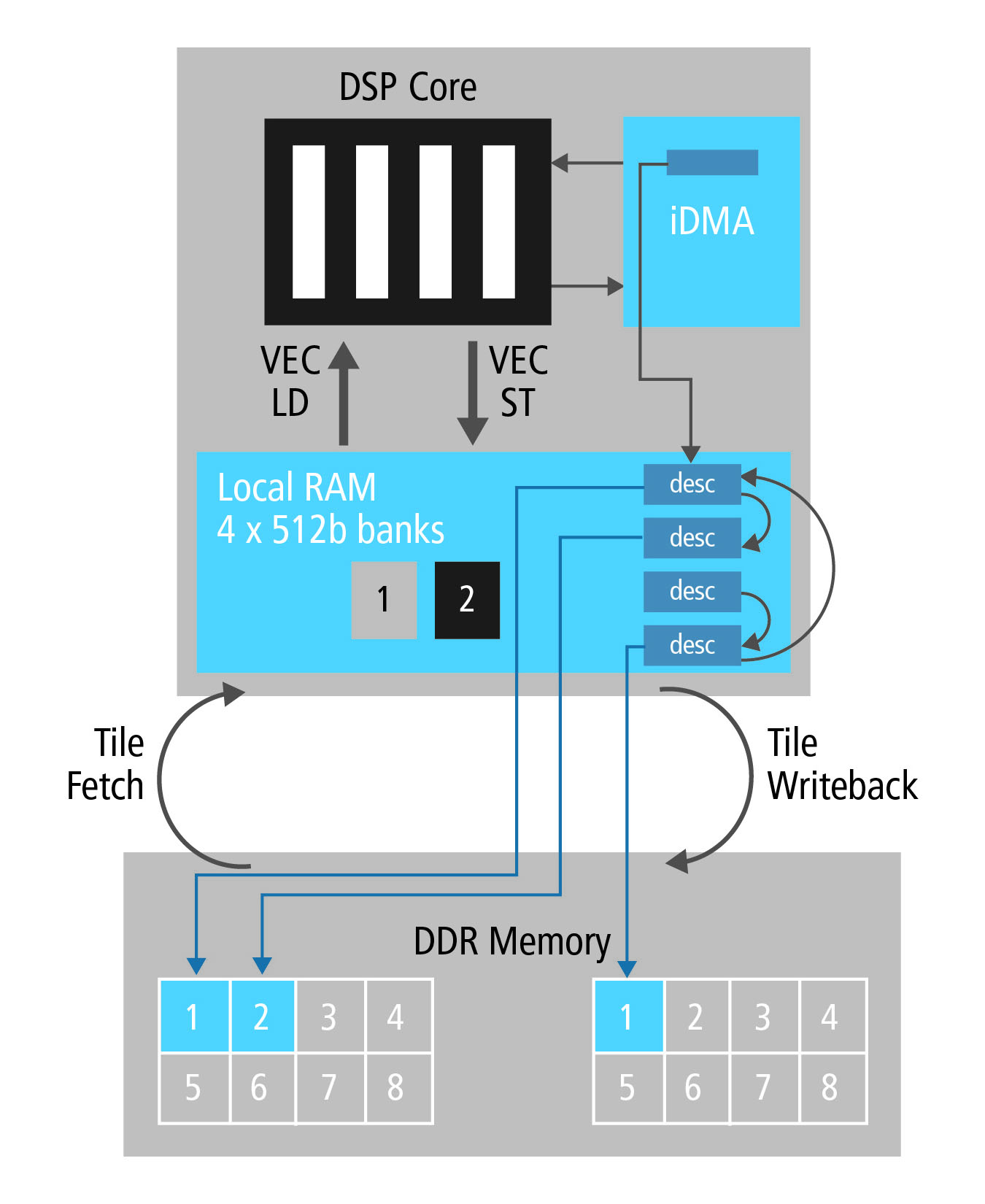
Attraverso l’intero flusso dell’algoritmo di rilevamento della corsia, i dati dell’immagine vengono elaborati utilizzando una tecnica denominata “tiling” e sfruttando le potenzialità dell’iDMA. Per l’elaborazione di dati SIMD di ampie dimensioni è necessario utilizzare istruzioni di load/store vettorizzare per accedere ai dati dell’immagine contenuti nella RAM locale mediante iterazioni continue (tight loop). Lo schema previsto dalla tecnica di “tiling” consente a una piccola parte dell’immagine di essere trasferita dalla più lenta memoria di sistema nelle RAM locali utilizzando il trasferimento di dati a blocchi supportato da iDMA.
Al fine di minimizzare l’impatto dell’accesso in memoria si è anche fatto ricorso a uno schema di DMA buffering di tipo ping-pong il cui funzionamento è riportato in figura 6. In uno schema di questo tipo il primo descrittore dell’iDMA è programmato per caricare (fetch) il “source tile 1” (in pratica un blocco di dati, si faccia riferimento alla Fig. 6) dalla memoria DDR al buffer ping presente nella RAM locale. Dopo il completamento della transazione DMA, il software DSP inizia l’elaborazione del buffer ping per il tile numero 1.
Nel frattempo, il secondo descrittore dell’iDMA è programmato per caricare il “source tile 2” dalla memoria DDR al buffer pong situato nella RAM locale. Poiché l’iDMA effettua il caricamento del secondo tile in parallelo con l’elaborazione DSP, di fatto “cela” la latenza legata all’accesso in memoria. La combinazione tra la tecnica di tiling e il DMA di tipo ping pong ha permesso di accelerare notevolmente (di un fattore compreso tra 15 e 20) l’esecuzione dell’algoritmo da parte del sistema hardware prototipale basato su FPGA.
{kind=link}
In questo articolo è stato presentato un algoritmo per il rilevamento della corsia, una funzionalità tipica di ogni sistema ADAS, per illustrare il flusso di sviluppo del software per visione artificiale e le problematiche che gli sviluppatori di algoritmi per visione artificiale devono affrontare per scegliere e implementare un algoritmo robusto che deve garantire prestazioni in real time pur con limitate risorse di sistema.
Sono stati inoltre evidenziate le potenzialità di Tensilica Vision DSP e le modalità di utilizzo della libreria software XI per eseguire in tempi brevi il porting e ottimizzare gli algoritmi di visione artificiale su un sistema hardware embedded. Il progetto di sviluppo dell’algoritmo per il rilevamento della corsia utilizzato nei sistemi ADAS è stato completato nell’arco di tre mesi da un progettista software che non aveva un’esperienza pregressa di programmazione del DSP Tensilica Vision.
I compiti da svolgere prevedevano analisi dell’applicazione e ricerca dell’algoritmo, prototipazione di quest’ultimo utilizzando MATLAB, sviluppo di codice C funzionale generico, ottimizzazione per Vision DSP, dimostrazione su una piattaforma hardware di prototipazione basata su FPGA. Grazie al supporto di caratteristiche hardware avanzate come DMA 2D e tecniche di programmazione come “tiling” e gestione del DMA buffer in modalità ping pong, è stato possibile dimostrare un’implementazione ottimizzata dell’algoritmo di rilevamento della corsia operante in real time su un hardware prototipale che opera a una frequenza molto inferiore rispetto a quella raggiungibile da Vision DSP integrato in un SoC.