Microelettronica in 12 puntate – 10: circuiti logici sequenziali
-

- Tweet
- Pin It
- Condividi per email
-
I circuiti logici combinatori hanno una proprietà che consiste nel fatto che l’uscita di un blocco è solo una funzione dei valori di ingresso correnti. Eppure, quasi tutti i sistemi utili richiedono memorizzazione di informazioni di stato, portando a un’altra classe di circuiti chiamati logici sequenziali. In questi circuiti, l’uscita dipende non solo dai valori correnti degli ingressi, ma anche dallo stato precedente. In altre parole, un circuito sequenziale ricorda alcune fasi della storia passata del sistema. Una varietà di scelte in circuiti sequenziali e metodologie rende la scelta corretta, che è sempre più importante nei moderni circuiti digitali, con un grande impatto sulle prestazioni, potenza e/o complessità di progettazione.
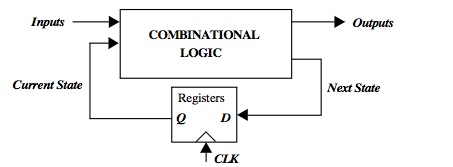
Fig, 1 – Layout generale di una macchina a stati finiti (FSM)
La figura 1 mostra uno schema a blocchi generale di una macchina a stati finiti (FSM) che consiste di una logica combinatoria e registri che contengono lo stato del sistema. Il sistema descritto appartiene alla classe dei sistemi sequenziali sincroni, in cui tutti i registri sono sotto il controllo di un singolo clock. Le uscite del FSM sono funzioni degli ingressi correnti e dello stato attuale. Sul fronte di salita del clock, i bit relativi allo stato successivo vengono copiati alle uscite dei registri (dopo un certo ritardo di propagazione). Il registro ignora quindi variazioni dei segnali di ingresso fino al successivo fronte di salita. In generale, i registri possono essere positive edge-triggered (dove i dati di ingresso vengono copiati sul fronte positivo) o negative edge-triggered (dove i dati di ingresso vengono copiati sul fronte di discesa del clock).
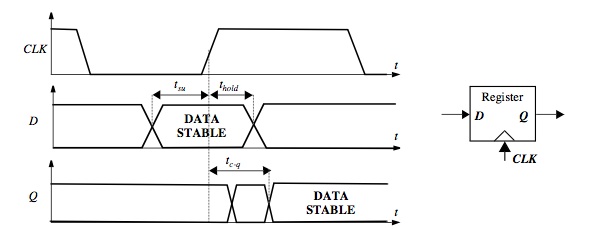
Fig. 2 – Definizione del tempo di set-up, hold time e ritardo di propagazione
In generale, ci sono tre parametri di temporizzazione importanti associati con un registro come illustrato in figura 2. Il tempo di set-up (tsu) è il tempo di validazione dei dati di ingresso (ingresso D) prima della transizione dal clock (questo è la transizione 0-1 per un registro edge-triggered positivo). Il tempo di attesa (Thold) è il tempo affinché i dati rimangono validi dopo il fronte di clock. Supponendo che i tempi di set-up e hold-time (attesa) siano soddisfatti, i dati in ingresso D vengono copiati all’uscita Q dopo il ritardo di propagazione (con riferimento al fronte del clock) indicato con tc–q.

Fig. 3 – Registro Master-Slave Based Edge Triggered
Registri Master-Slave Based Edge Triggered
L’approccio più comune per la costruzione di un registro edge-triggered è di utilizzare una configurazione master-slave, come mostrato nella figura 3. Il registro è composto da un latch positivo e uno negativo posti in cascata. Nella fase bassa del clock, la fase master è trasparente e l’ingresso D viene trasmesso all’uscita, QM. Durante questo periodo, lo stadio slave è in modalità di attesa, mantenendo il suo valore precedente con il sistema di retroazione.
Sul fronte di salita del clock, il master smette di campionare l’ingresso, e lo slave inizia la fase di campionamento. Durante la fase alta del clock, lo slave campiona il segnale in ingresso mentre il master rimane in attesa. Poiché QM è costante durante la fase alta del clock, l’uscita Q rende una sola transizione per ciclo. Un registro negative edge-triggered può essere costruito utilizzando lo stesso principio semplicemente commutando l’ordine del latch positivo e negativo.
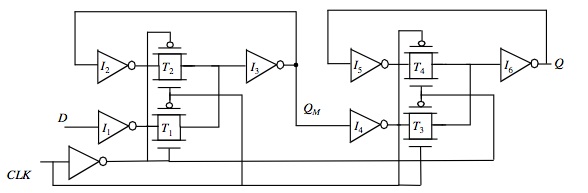
Fig. 4 – Implementazione di un registro Master-Slave Based positive-edge triggered con multiplexer
Un’implementazione completa di un registro master-slave positive-edge triggered con multiplexers è visualizzata in figura 4. Il multiplexer è configurato utilizzando dei gate di trasmissione.
Registri e latch dinamici
Gli storage in un circuito sequenziale statico si basano sul concetto che una coppia di invertitori ad accoppiamento incrociato produce un elemento bistabile e può quindi essere utilizzata per memorizzare valori binari. Questo approccio ha la proprietà che un valore memorizzato rimane valido finché la tensione di alimentazione è applicata al circuito, da cui il nome statico. Il principale svantaggio, tuttavia, è la sua complessità. Quando i registri vengono utilizzati in strutture di calcolo che sono costantemente sotto un clock come struttura pipeline, il requisito che la memoria dovrebbe mantenere lo stato per lunghi periodi di tempo può essere significativamente meno rigido.
Ciò si traduce in una classe di circuiti basati su un deposito temporaneo di carica sulla capacità parassita. Il principio è identico a quello utilizzato nella logica dinamica: la carica immagazzinata in un condensatore può essere utilizzata per rappresentare un segnale logico. L’assenza di carica denota uno 0 logico, mentre la sua presenza significa un bit 1. Il condensatore non è ideale, purtroppo, e qualche perdita di carica è sempre presente.
Un valore memorizzato può, quindi, essere mantenuto solo per un limitato periodo di tempo, tipicamente nell’intervallo di millisecondi. Se si vuole preservare l’integrità del segnale è necessario un aggiornamento periodico del suo valore. Da qui il nome di storage dinamico. La lettura del segnale memorizzato da un condensatore senza interrompere la carica, richiede la disponibilità di un dispositivo con un’elevata impedenza di ingresso.
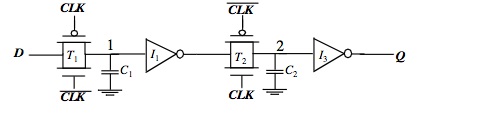
Fig. 5 – Registro edge-trigger dinamico
Un registro completamente dinamico positive edge-triggered basato sul concetto master-slave è mostrato nella figura 5. Quando CLK = 0, i dati di ingresso vengono campionati sul nodo di archiviazione 1, che ha una capacità equivalente di C1 costituito dalla capacità di gate di I1, la capacità di giunzione e di gate di T1. Durante questo periodo, lo stadio slave è in una modalità di attesa, con un nodo 2 in alta impedenza.
Sul fronte di salita del clock, T2 si accende, e il valore campionato sul nodo 1 si propaga all’uscita Q. Il nodo 2 memorizza, successivamente, la versione invertita del nodo 1. Questa implementazione di un registro edge-triggered è molto efficiente in quanto richiede solo 8 transistor. Gli switch di campionamento possono essere implementati usando strutture NMOS. Il numero di transistor ridotto è attraente per sistemi ad alte prestazioni e bassa potenza.

Fig. 6 – Pulse registrer
Pipelining
Fino ad ora abbiamo utilizzato la configurazione master-slave per creare registri edge-triggered. Un approccio completamente diverso per la costruzione di un registro è l’utilizzo di segnali impulsivi. L’idea è di costruire un breve impulso intorno al fronte di salita (o di discesa) del clock. Questo impulso agisce come ingresso di clock per un latch, campionando l’ingresso solo in una breve finestra, mantenendo a sua volta il tempo di apertura del latch molto breve (Fig. 6).
Pipelining è una tecnica di progettazione popolare spesso utilizzata per accelerare il funzionamento dei percorsi in data-processing digitali. L’idea è facilmente spiegabile con l’esempio della figura 7. L’obiettivo del circuito presentato è quello di calcolare log (| a – b |), dove entrambi a e b rappresentano flussi di numeri, il calcolo deve essere eseguito su un ampio set di valori.

Fig. 7 – Digital Data-path per versione non-pipelined (sopra) e pipelined (sotto)
Pipelining è una tecnica per migliorare l’utilizzo delle risorse e aumentare il throughput funzionale. Supponiamo di introdurre registri tra i blocchi logici, come mostrato nella figura 7. Il vantaggio di funzionamento pipeline diventa evidente in sede di esame del minimo periodo di clock. Il blocco del circuito combinatorio è partizionato in tre sezioni, ciascuna delle quali ha un ritardo di propagazione più piccolo rispetto alla funzione originale.
Supponiamo che tutti i blocchi logici abbiano approssimativamente lo stesso ritardo di propagazione. La rete pipeline supera il circuito originale di un fattore tre sotto queste ipotesi. L’aumento delle prestazioni avviene a costi relativamente piccoli con due registri supplementari, e un aumento della latenza. Questo spiega perché il pipelining è popolare nelll’attuazione di datapath high performance.
Maurizio Di Paolo Emilio
Contenuti correlati
-
 Microelettronica in 12 puntate – 12: Considerazioni sui regolatori di tensione
Microelettronica in 12 puntate – 12: Considerazioni sui regolatori di tensioneNonostante i crescenti livelli di integrazione dei semiconduttori e sistemi su chip per molte applicazioni prontamente disponibili, oltre alla crescente disponibilità di schede di sviluppo altamente presenti, si richiede ancora un PCB personalizzato. Anche per sviluppi “una...
-
 Microelettronica in 12 puntate – 11: Considerazioni sui regolatori di tensione
Microelettronica in 12 puntate – 11: Considerazioni sui regolatori di tensioneUn regolatore di tensione è progettato per mantenere automaticamente un livello di tensione costante. Può essere un semplice “feed-forward” o può includere cicli di controllo di feedback. In accordo al design, esso può essere utilizzato per regolare...
-
Microelettronica in 12 puntate – 9: circuito integratore
Nei precedenti tutorial abbiamo visto circuiti che mostrano l’’utilizzo di un amplificatore operazionale come parte di uno stage di amplificazione a retroazione positiva (trigger schmitt) o negativa come un circuito sommatore o tipo sottrattore. Ma se dovessimo...
-
Microelettronica in 12 puntate – 8: amplificatori MOSFET common source
Nelle puntate precedenti abbiamo visto le configurazioni generali degli stadi di amplificazione con MOSFET. In questo nuovo articolo approfondiremo la parte di analisi del common source di un MOSFET NMOS. Tutte le considerazioni saranno effettuate nel regime...
-
Microelettronica in 12 puntate – 7: amplificatori operazionali, circuiti e IC commerciali
Continuiamo il nostro percorso, iniziato nell’articolo precedente, con gli amplificatori operazionali (op-amp). In questa nuova puntata valuteremo i principali circuiti e alcuni IC che troviamo in commercio, con una valutazione generale degli aspetti commerciali in termini di...
-
Microelettronica in 12 puntate – 6: amplificatori operazionali, generalità
Un amplificatore operazionale elabora piccoli segnali in modo differenziale, fornendo in uscita lo sviluppo di un singolo segnale ended (Fig. 1). Mentre gli amplificatori operazionali reali derivano dalle sue caratteristiche ideali, è molto utile, per un primo...
-
Microelettronica in 12 puntate – 5: stadi di amplificazione con sistemi MOS
La preponderanza di amplificatori lineari realizzati in tecnologia MOSFET comprende interconnessioni in 3 principali configurazioni: common source, common drain e common gate. In un amplificatore a source comune, per esempio, il segnale di ingresso è il segnale...
-
Microelettronica in 12 puntate – 4: specchio di corrente
Una caratteristica importante è la resistenza di uscita relativamente elevata che aiuta a mantenere costante la corrente di uscita indipendentemente dalle condizioni di carico. Altre caratteristiche peculiari sono la sua semplicità e il fatto che una semplice...
-
Microelettronica in 12 puntate – 3: tecnologia Mosfet
I Mosfet, acronimo per Metal-Oxide-Semiconductor Field-Effect-Transistor (transistor a effetto di campo di tipo metallo-ossido-semiconduttore), devono la loro popolarità sempre crescente alle ottime caratteristiche elettriche, quale la elevata impedenza di ingresso. Le principali applicazioni sono nel campo automobilistico,...
-
Microelettronica in 12 puntate – 2: circuiti raddrizzatori
I circuiti raddrizzatori a diodi sono ampiamente utilizzati nella progettazione elettronica, in particolare nei sistemi di alimentazione e di demodulazione. L’obiettivo principale è la conversione del segnale AC in DC, che può essere realizzata con diverse configurazioni...
Scopri le novità scelte per te
-
Microelettronica in 12 puntate – 12: Considerazioni sui regolatori di tensione
Nonostante i crescenti livelli di integrazione dei semiconduttori e sistemi su chip per molte applicazioni prontamente disponibili,...
-
Microelettronica in 12 puntate – 11: Considerazioni sui regolatori di tensione
Un regolatore di tensione è progettato per mantenere automaticamente un livello di tensione costante. Può essere un...

News/Analysis Tutti ▶
-
 Nuovo stabilimento di LEM in Malesia
Nuovo stabilimento di LEM in MalesiaLEM ha inaugurato un nuovo stabilimento per semiconduttori nello stato di Penang (Malesia), frutto...
-
 EET Group presenta il suo nuovo configuratore rack
EET Group presenta il suo nuovo configuratore rackEET Group ha realizzato un configuratore online per rack progettato per semplificare la ricerca...
-
 L’Industria 5.0 in un sondaggio di element14 Community
L’Industria 5.0 in un sondaggio di element14 CommunityFarnell ha recentemente condotto un sondaggio della element14 Community per valutare l’opinione attuale del...
Products Tutti ▶
-
 Un nuovo condensatore MLCC da Samsung Electro-Mechanics
Un nuovo condensatore MLCC da Samsung Electro-MechanicsSamsung Electro-Mechanics ha presentato CL32C223JIV1PN#, un nuovo condensatore ceramico multistrato (MLCC) ad alte prestazioni...
-
 Microchip facilita l’integrazione USB nei sistemi embedded
Microchip facilita l’integrazione USB nei sistemi embeddedMicrochip Technology ha presentato la famiglia di microcontroller AVR DU con funzionalità USB (come...
-
 Microchip migliora la sicurezza dei prodotti IoT
Microchip migliora la sicurezza dei prodotti IoTMicrochip Technology ha ampliato la sua offerta Trust Platform aggiungendo ECC608 TrustMANAGER con Kudelski...