Core multipli standardizzati
Si può sfruttare al massimo l’impostazione in parallelo dei multicore se tutto l’ambiente che li circonda soddisfa le linee guida redatte dalla Multicore Association
-

- Tweet
- Pin It
- Condividi per email
-

Le architetture multicore rappresentano senza dubbio un importante passo avanti nell’evoluzione delle prestazioni dei sistemi embedded perché, grazie al parallelismo a livello hardware, è possibile eseguire più funzioni simultaneamente e accelerare l’esecuzione degli algoritmi. Ciò, tuttavia, costringe gli sviluppatori a strutturare i programmi in modo tale da offrire diversi gradi di parallelismo affinché gli algoritmi possano adattarsi al livello di parallelismo disponibile nell’hardware.

Fig. 1 – L’obiettivo della Multicore Association è offrire ai costruttori delle linee guida su come uniformare tutti gli aspetti delle moderne architetture in parallelo
Di fatto, questo ha però favorito la diversificazione del software applicativo, al punto da ripercuotersi su un’esagerata personalizzazione delle funzioni di elaborazione e di controllo delle interfacce, anche a livello dei tool di sviluppo. Questa tendenza può forse compiacere ai costruttori che mirano a difendere quanto più possibile la loro proprietà intellettuale ma può essere invece d’intralcio a chi deve sviluppare applicazioni per il vasto quanto variopinto settore embedded.
In effetti, soprattutto in ambito industriale, capita spesso di dover far andare d’accordo da entrambi i punti di vista hardware e software le schede di diversi costruttori ed è perciò necessaria l’interoperabilità fra tutte le parti in gioco.
La Multicore Association ha tenuto la sua prima riunione a San Jose, in California, il 16 maggio 2005 ed è oggi sostenuta da numerosi leader nel settore delle architetture multicore e da tanti protagonisti nello sviluppo delle applicazioni embedded, oltre che da più università e centri di ricerca internazionali. Fra tutti citiamo AMD, ENEA, Freescale Semiconductor, IMEC, Intel, National Instruments, Siemens, Texas Instruments e Wind River.
In questo decennio si è dedicata a tracciare un approccio standardizzato per tutti gli aspetti che sono in qualche modo coinvolti dalla struttura multicore delle architetture di calcolo. L’obiettivo è di fare in modo che anche le interfacce periferiche attorno ai multicore e i tool di sviluppo a essi dedicati possano avere connotazioni sufficientemente standard per permettere lo sviluppo di applicazioni interoperabili, anche se basate su parti fornite da diversi costruttori.
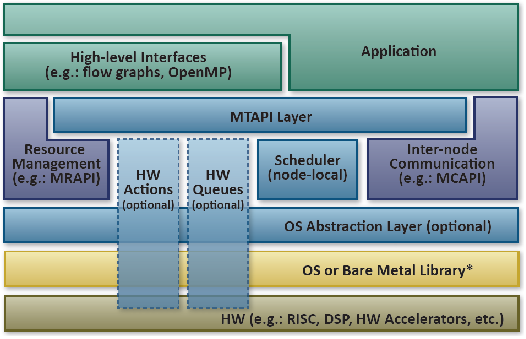
Fig. 2 – La standardizzazione della gestione delle Task consente di implementare applicazioni portabili sia nell’hardware che nel software e realizzare facilmente schede con chip e interfacce di diversi costruttori
Standard multicore
Le prime più importanti normative promosse da questo consorzio sono denominate con gli acronimi dei gruppi di lavoro che le hanno redatte e continuano oggi a metterle a punto: MTAPI (Multicore Task Management Api Working Group), MCAPI (Multicore Communications Api Working Group), MRAPI (Multicore Resource Management Api Working Group), SHIM (Software-Hardware Interface for Multi-Many-Core Working Group), TIWG (Tools Infrastructure Working Group), MPP (Multicore Programming Practices Group) e MVWG (Multicore Virtualization Working Group).
Il MTAPI Working Group cerca di normare il parallelismo fra le task eseguibili in modo tale da poterlo trasformare nella configurazione di opportune API (Application Programming Interface) in grado di consentire allo sviluppatore di gestire i processi sincroni e asincroni, nonché quelli simmetrici e asimmetrici al fine di rendere più controllabile la suddivisione delle task fra i core multipli.
In pratica, le MTAPI sono delle API pensate per le esigenze degli sviluppatori di applicazioni embedded alle prese con le architetture multicore omogenee ed eterogenee e semplificano la schedulazione delle task da eseguire nei singoli core migliorandone le prestazioni in tempo reale.

Fig. 3 – Il Multicore Task Management API Working Group ha concepito una struttura pseudo-piramidale di opportune API che semplificano la suddivisione e la gestione delle task fra i core
Nel dettaglio specificano l’attività di ciascun core con una struttura pseudo-piramidale composta dai “Job” che sono i “lavori” da eseguire o a livello software o in hardware oppure in varie porzioni suddivise fra entrambi i contesti. Queste porzioni contenute nei Job sono le “Action” che si differenziano nettamente fra quelle software e quelle hardware, ma entrambe possono essere invocate da una “Task” ossia da un’attività operativa che le abilita affinché siano eseguite e poi a esecuzione ultimata le disabilita.
Ogni qual volta vi siano altre Task già in esecuzione allora le successive diventano “Queue” e formano una coda strutturata in più parti che può coinvolgere simultaneamente in parallelo diversi core e più Action di entrambi i tipi, software e hardware. Le direttive delineate da questo gruppo di lavoro spiegano come strutturare il tutto, come scrivere le istruzioni di chiamata e di indirizzamento, come impostare la suddivisione delle attività fra i core e come gestire le priorità fra le Task singole e le Task composite.
Le MCAPI servono per standardizzare i trasferimenti fra i core, fra i chip o fra le schede e permettere la portabilità dei protocolli nei differenti sistemi di comunicazione implementati evitando sul nascere gli errori di sincronizzazione. Le MRAPI permettono di gestire le risorse disponibili nei diversi core, in modo tale da non creare conflitti di accesso a uno stesso core, oppure lasciare un core inutilizzato mentre ce ne sono altri con code di istruzioni in attesa.
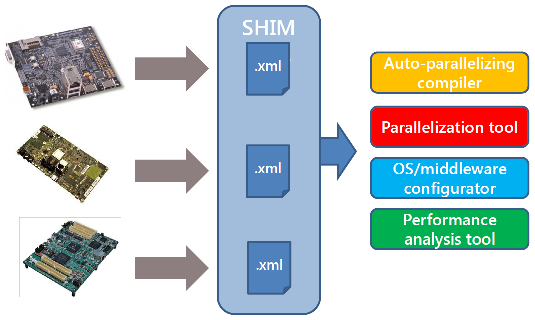
Fig. 4 – Affinché vi sia vera interoperabilità occorre che i tool di sviluppo consentano di realizzare applicazioni strutturate in parallelo anche nella gestione delle interfacce e nella virtualizzazione delle funzioni
Le SHIM sono state pensate per consentire ai costruttori di microprocessori e microcontrollori multicore e manycore di collaborare insieme ai fornitori di tool di sviluppo software, in modo tale da trovare delle linee guida comuni alle quali assoggettare i propri prodotti da entrambi i punti di vista hardware e software, almeno durante il ciclo di sviluppo.
In pratica, viene proposta una descrizione dell’intera architettura multicore dal punto di vista software che comprende anche le descrizioni dei processi a livello hardware, come le comunicazioni fra i core, i trasferimenti da e verso memorie strutturate oppure le funzionalità di rete. Le specifiche SHIM sono pubbliche e aperte a tutti i protocolli di sistema ma offrono anche la possibilità di definire alcune informazioni su talune funzionalità come confidenziali e in tal modo renderle accessibili solo a chi ne vuole tutelare la proprietà intellettuale.
Multicore orientati al futuro
Il gruppo di lavoro TIWG intende promuovere un’evoluzione indispensabile a livello dei tool di sviluppo e fare in modo che dentro tutti i tool esistenti e soprattutto in quelli nuovi di prossima uscita ci sia un supporto per poter trasformare le applicazioni embedded sequenziali in una forma adatta all’esecuzione in parallelo su più core.
In questo modo sarà più semplice realizzare software con caratteristiche adatte al calcolo parallelo e conformi al parallelismo fra i core a livello hardware. Il TIWG sta collaborando attivamente con il CE Linux Forum per sviluppare delle specifiche particolarmente adatte alle applicazioni industriali. Nel frattempo, l’MPP Working Group sta realizzando una guida contenente un gran numero di regole pratiche, consigli, suggerimenti ed esempi che possono aiutare gli ingegneri e i progettisti a realizzare applicazioni in grado di sfruttare appieno i vantaggi delle architetture multicore.
Un’ampia sezione è dedicata ai metodi con cui imparare a scrivere i programmi in C/C++ in modo che siano “multicore ready” e offrano funzionalità in parallelo ad alto livello potenti, veloci e affidabili. Con questa guida si può imparare rapidamente a programmare in parallelo e realizzare programmi portabili su tutte le piattaforme standardizzate con le tecniche della Multicore Association.
È senza dubbio orientato alle prossime generazioni di multicore il lavoro dell’MVWG dato che cerca di mettere a punto delle linee guida sulla virtualizzazione delle task nei processi di calcolo. Gli ambiti in cui stanno focalizzando le ricerche sono per ora due denominati “Classifying Virtualization-related Features Implemented Within Processors” e “Linux Modules as Proof of Concept”.
Il primo è senza dubbio il più impegnativo perché oggi alcuni costruttori stanno implementando tecniche di virtualizzazione proprietarie e molto diverse fra loro sia nell’impostazione sia nella diversificazione fra quelle per i core e quelle per gli I/O. L’intenzione del gruppo di lavoro è di catalogare le varie tecniche già in uso e poi cercare di regolamentarne l’utilizzo in modo che almeno le procedure fondamentali siano compatibili e interoperabili.
Il secondo iter di normalizzazione parte dal presupposto che per supportare la virtualizzazione delle funzionalità occorrono necessariamente un Hypervisor, un Real Time OS e un Feature Rich OS ovvero un algoritmo di supervisione e un sistema operativo in tempo reale che sia anche particolarmente ricco di funzionalità. Pertanto hanno deciso di sviluppare delle metodologie basate su Linux che possano aiutare gli sviluppatori a dare alla virtualizzazione una connotazione almeno in gran parte standardizzata senza appesantire i costi di sviluppo.
I sistemi embedded realizzati tenendo conto delle linee guida stabilite dai Working Group della Multicore Association possono essere composti da parti di diversi costruttori perfettamente in grado di interoperare e ciò significa che se ne può analizzare la qualità delle prestazioni e confrontarla con altre soluzioni, magari dopo aver introdotto delle modifiche sostituendo un chip, una memoria e/o un’interfaccia con alternative di altri costruttori. La possibilità di confrontare alla pari le prestazioni può essere molto importante nelle applicazioni industriali con funzionalità fortemente specializzate.
Lucio Pellizzari

News/Analysis Tutti ▶
-
 La soluzione wireless per il trattamento dell’aria da Emerson e CoreTigo
La soluzione wireless per il trattamento dell’aria da Emerson e CoreTigoEmerson e CoreTigo hanno sviluppato congiuntamente una soluzione che migliora le unità di regolazione...
-
 Disponibili da Farnell i nuovi kit di saldatura WXsmart Weller
Disponibili da Farnell i nuovi kit di saldatura WXsmart WellerFarnell ha aggiunto alla sua offerta i cinque nuovi kit di stazioni di saldatura...
-
 EnGenius presenta la nuova linea di Power Distribution Units
EnGenius presenta la nuova linea di Power Distribution UnitsEnGenius ha ampliato la sua gamma di prodotti con la nuova linea di Power...
Products Tutti ▶
-
 Un nuovo condensatore MLCC da Samsung Electro-Mechanics
Un nuovo condensatore MLCC da Samsung Electro-MechanicsSamsung Electro-Mechanics ha presentato CL32C223JIV1PN#, un nuovo condensatore ceramico multistrato (MLCC) ad alte prestazioni...
-
 Microchip facilita l’integrazione USB nei sistemi embedded
Microchip facilita l’integrazione USB nei sistemi embeddedMicrochip Technology ha presentato la famiglia di microcontroller AVR DU con funzionalità USB (come...
-
 Microchip migliora la sicurezza dei prodotti IoT
Microchip migliora la sicurezza dei prodotti IoTMicrochip Technology ha ampliato la sua offerta Trust Platform aggiungendo ECC608 TrustMANAGER con Kudelski...

{kind=link}